

Published: Jul 29, 2025 by Isaac Johnson
Recently the Qwen project announced Qwen3-Coder. The blog said it was forked from “Gemini Code”, but I’m sure they meant Gemini CLI.
Today we’ll test out QWen coder and attempt to use it against local backends, Azure, Google and even the paid AliCloud backend. We’ll look at usage and costs and compare a bit to Gemini CLI, Claude Code and Ollama.
We’ll wrap with cost considerations and how to send telemetry through Alloy to Datadog for monitoring.
Let’s start with the setup
Setup
All Qwen3-Coder needs is NodeJS 20+.
I can use nvm to verify that. Since we worked on the Open-Source PyBSPoster recently, let’s do something different and look at my code for the Fika meet app.
builder@LuiGi:~/Workspaces/flaskAppBase$ nvm list
v16.20.2
v18.20.2
-> v21.7.3
system
default -> stable (-> v21.7.3)
iojs -> N/A (default)
unstable -> N/A (default)
node -> stable (-> v21.7.3) (default)
stable -> 21.7 (-> v21.7.3) (default)
lts/* -> lts/iron (-> N/A)
lts/argon -> v4.9.1 (-> N/A)
lts/boron -> v6.17.1 (-> N/A)
lts/carbon -> v8.17.0 (-> N/A)
lts/dubnium -> v10.24.1 (-> N/A)
lts/erbium -> v12.22.12 (-> N/A)
lts/fermium -> v14.21.3 (-> N/A)
lts/gallium -> v16.20.2
lts/hydrogen -> v18.20.4 (-> N/A)
lts/iron -> v20.15.1 (-> N/A)
We now need to install Qwen3-Coder
$ npm i -g @qwen-code/qwen-code
added 1 package in 1s
npm notice
npm notice New major version of npm available! 10.5.0 -> 11.4.2
npm notice Changelog: https://github.com/npm/cli/releases/tag/v11.4.2
npm notice Run npm install -g npm@11.4.2 to update!
npm notice
Using with OpenAI SDK
export OPENAI_API_KEY="your_api_key_here"
export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
export OPENAI_MODEL="qwen3-coder-plus"
For this tool, I’ll create a new API key in my project settings
I just need to give it a name and pick a project (if I have more than one)
I checked the API reference to ensure I knew what my BASE URL should be
export OPENAI_API_KEY="sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxx"
export OPENAI_BASE_URL="https://api.openai.com/v1"
export OPENAI_MODEL="qwen3-coder-plus"
Usage
Now when I launch qwen I get some setup steps
My first attempt at usage was denied as it suggested I did not have access to that model
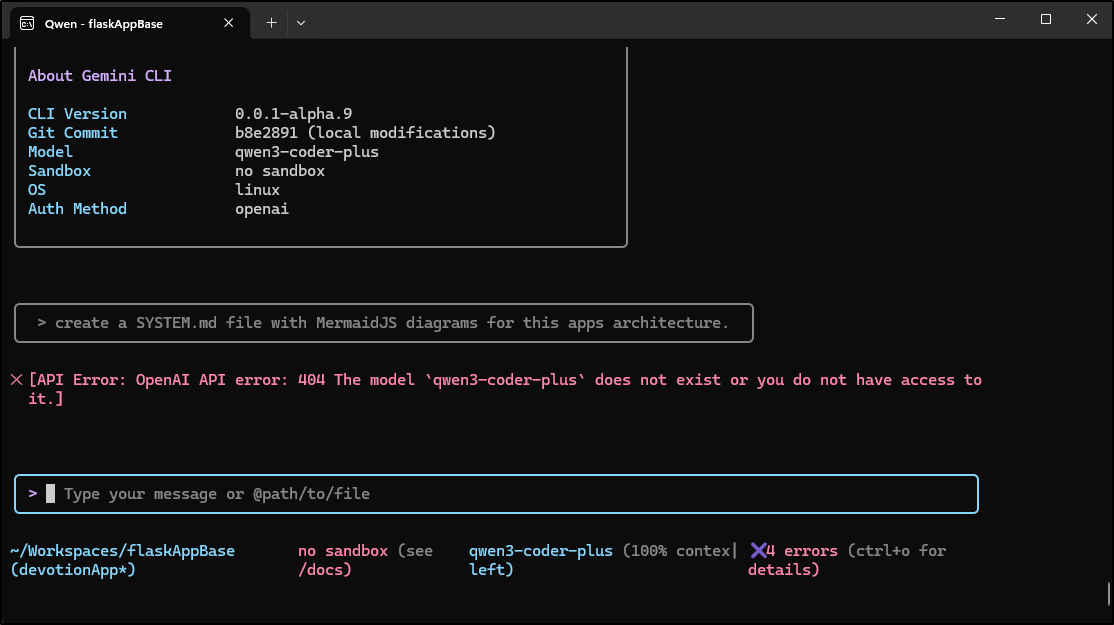
I feel like I’m missing something because there is no model of that name in OpenAI’s model library - so maybe they just use the SDK, but not OpenAI?
$ curl https://api.openai.com/v1/models -H "Authorization: Bearer sk-proj-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxx" | jq -r .data[].id | sort
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9702 100 9702 0 0 28753 0 --:--:-- --:--:-- --:--:-- 28789
babbage-002
chatgpt-4o-latest
codex-mini-latest
dall-e-2
dall-e-3
davinci-002
gpt-3.5-turbo
gpt-3.5-turbo-0125
gpt-3.5-turbo-1106
gpt-3.5-turbo-16k
gpt-3.5-turbo-instruct
gpt-3.5-turbo-instruct-0914
gpt-4
gpt-4-0125-preview
gpt-4-0613
gpt-4-1106-preview
gpt-4-turbo
gpt-4-turbo-2024-04-09
gpt-4-turbo-preview
gpt-4.1
gpt-4.1-2025-04-14
gpt-4.1-mini
gpt-4.1-mini-2025-04-14
gpt-4.1-nano
gpt-4.1-nano-2025-04-14
gpt-4o
gpt-4o-2024-05-13
gpt-4o-2024-08-06
gpt-4o-2024-11-20
gpt-4o-audio-preview
gpt-4o-audio-preview-2024-10-01
gpt-4o-audio-preview-2024-12-17
gpt-4o-audio-preview-2025-06-03
gpt-4o-mini
gpt-4o-mini-2024-07-18
gpt-4o-mini-audio-preview
gpt-4o-mini-audio-preview-2024-12-17
gpt-4o-mini-realtime-preview
gpt-4o-mini-realtime-preview-2024-12-17
gpt-4o-mini-search-preview
gpt-4o-mini-search-preview-2025-03-11
gpt-4o-mini-transcribe
gpt-4o-mini-tts
gpt-4o-realtime-preview
gpt-4o-realtime-preview-2024-10-01
gpt-4o-realtime-preview-2024-12-17
gpt-4o-realtime-preview-2025-06-03
gpt-4o-search-preview
gpt-4o-search-preview-2025-03-11
gpt-4o-transcribe
gpt-image-1
o1
o1-2024-12-17
o1-mini
o1-mini-2024-09-12
o1-preview
o1-preview-2024-09-12
o1-pro
o1-pro-2025-03-19
o3-mini
o3-mini-2025-01-31
o4-mini
o4-mini-2025-04-16
o4-mini-deep-research
o4-mini-deep-research-2025-06-26
omni-moderation-2024-09-26
omni-moderation-latest
text-embedding-3-large
text-embedding-3-small
text-embedding-ada-002
tts-1
tts-1-1106
tts-1-hd
tts-1-hd-1106
whisper-1
I also checked Azure AI Foundry which has other models
I also see Qwen3, but not a (real) coder on Ollama
Alicloud
Qwen comes from AliCloud, so maybe I just try using their cloud
I can activate a free trial
Which brings me to The Alibaba Cloud Model Studio
Free gift? I love free gifts
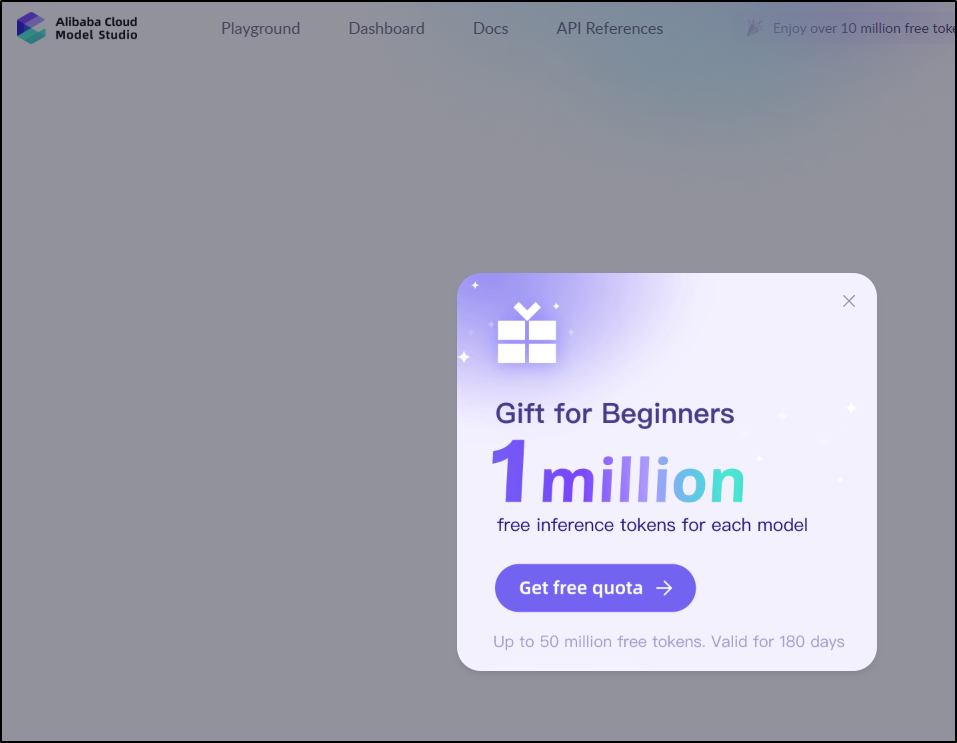
I can see the “Qwen3-Coder-Plus” is listed there
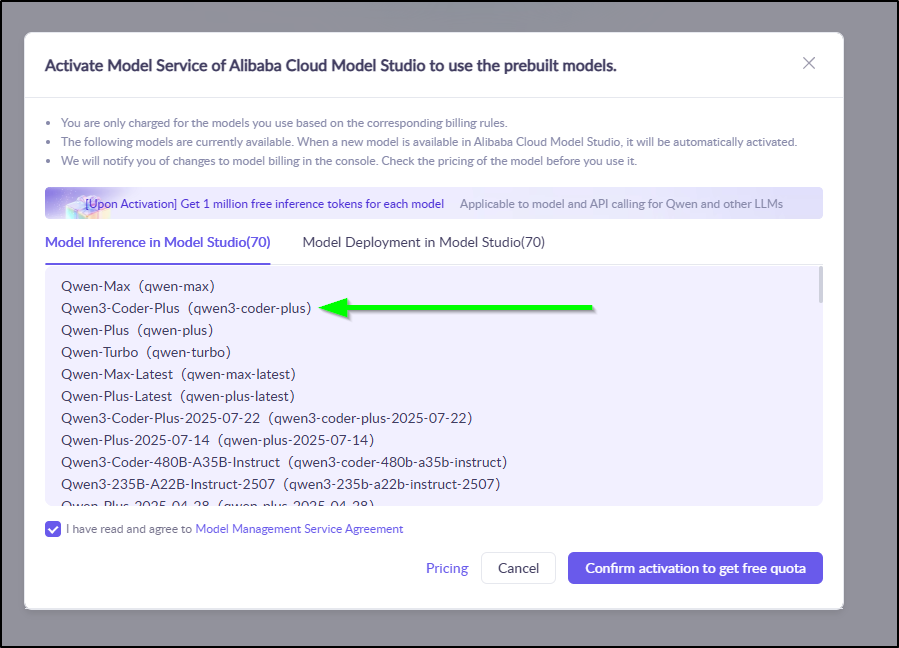
I’m a bit nervous about adding a payment method as that seems to be blocking my “free gift”
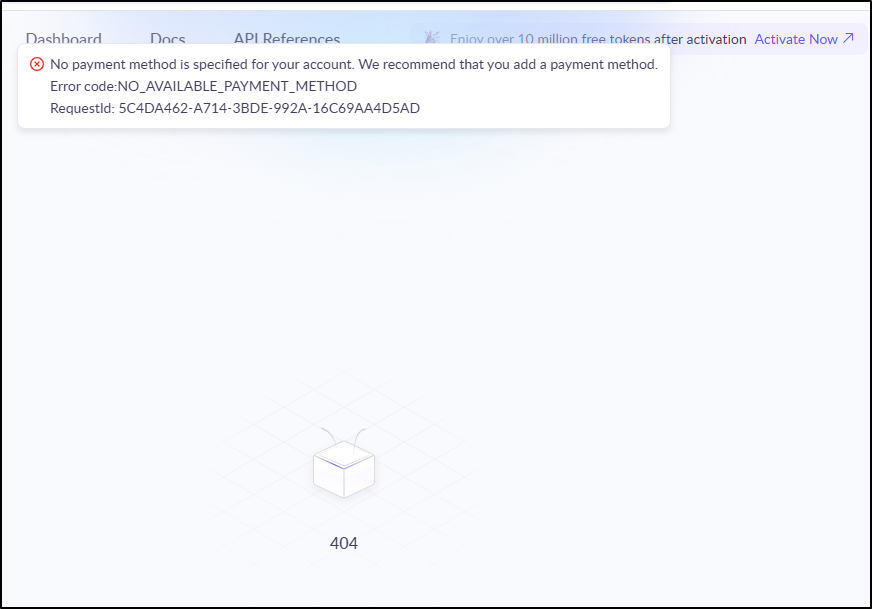
I took care of that and then activated the tokens. Next, I needed to create an API key
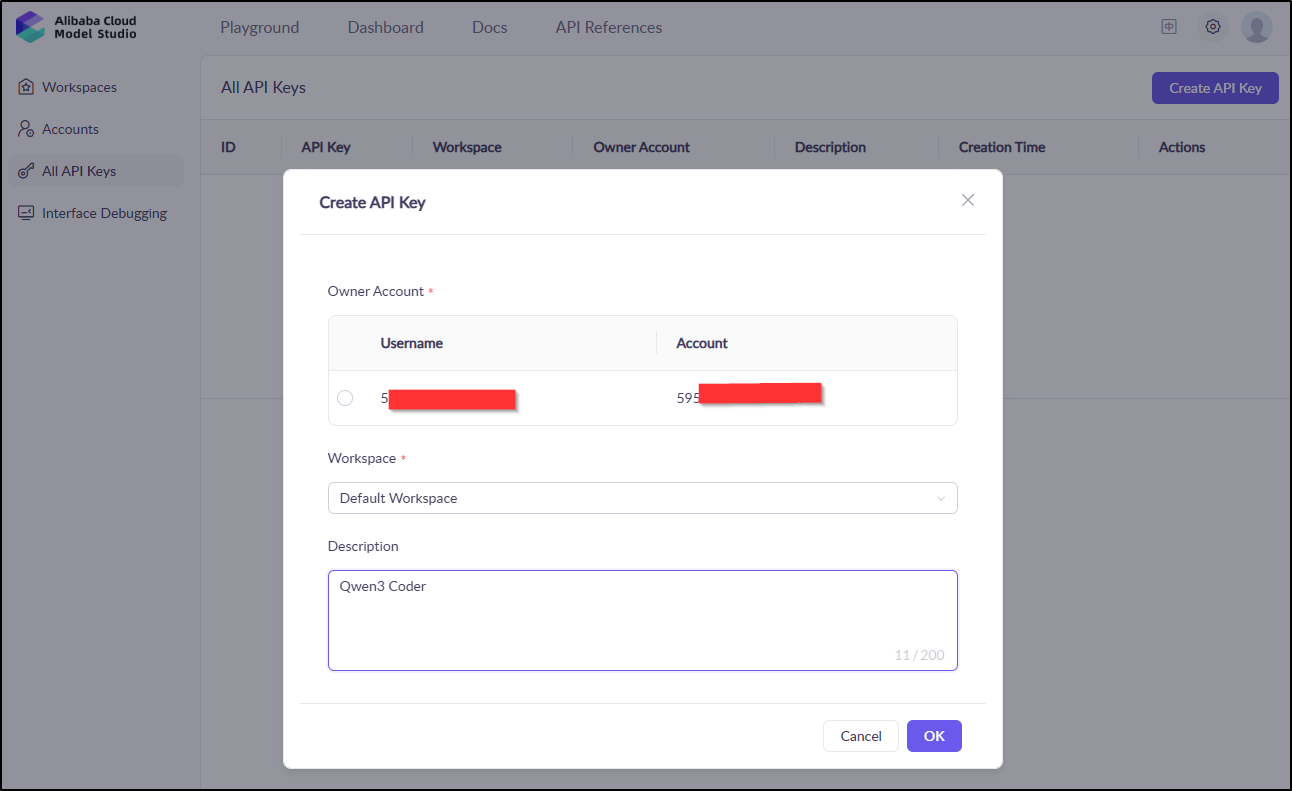
I’ll now use Alibaba cloud
$ export OPENAI_API_KEY='sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
$ export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
$ export OPENAI_MODEL="qwen3-coder-plus"
Usage
Let’s again try to do the System model in a diagram test with this app but this time using Qwen3 instead of Gemini Pro
This took about 185k tokens
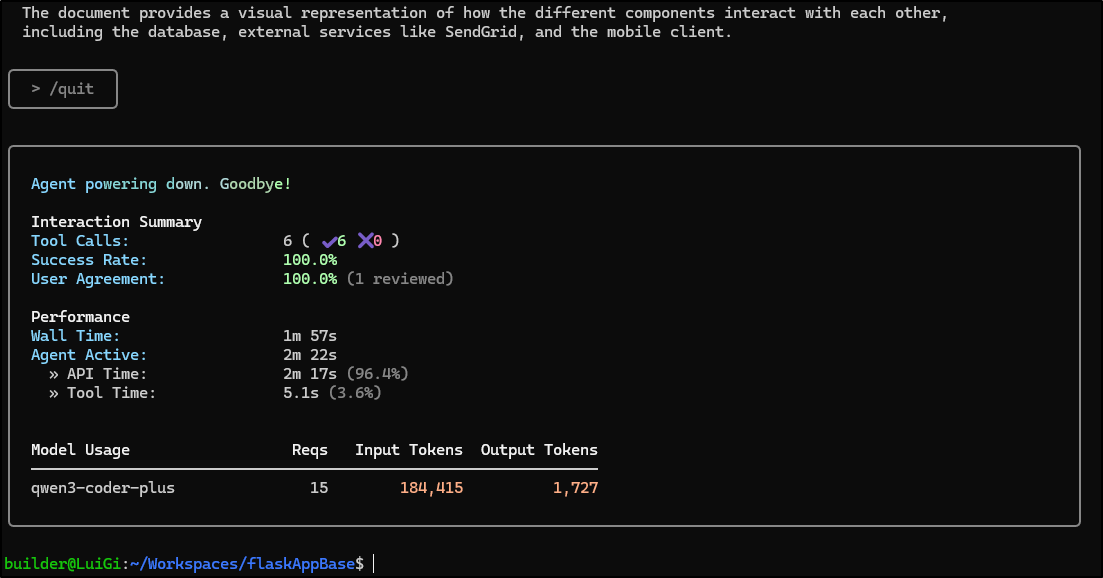
In these first few minutes after running Qwen3 Coder, I do not see any details in my Model Studio usage page
I’ll be sure to check back later…
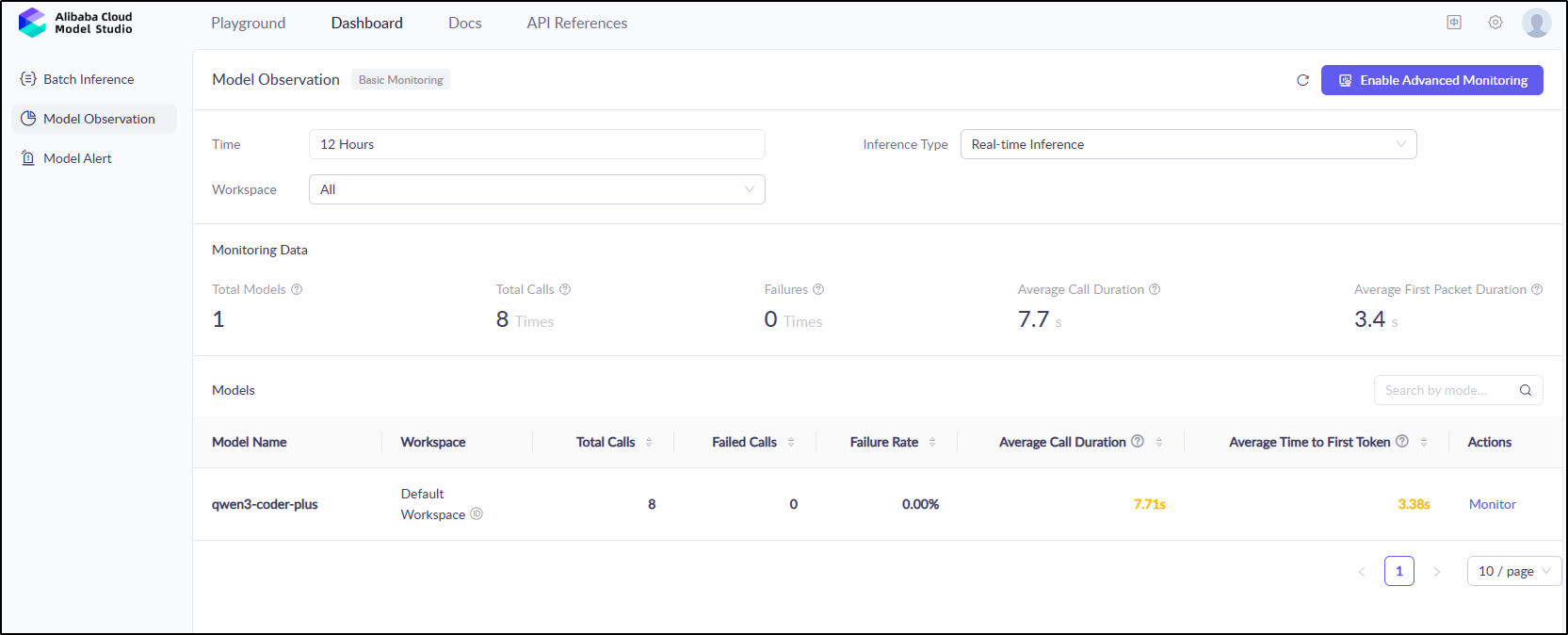
Clicking “monitor” confirms my guess on total tokens
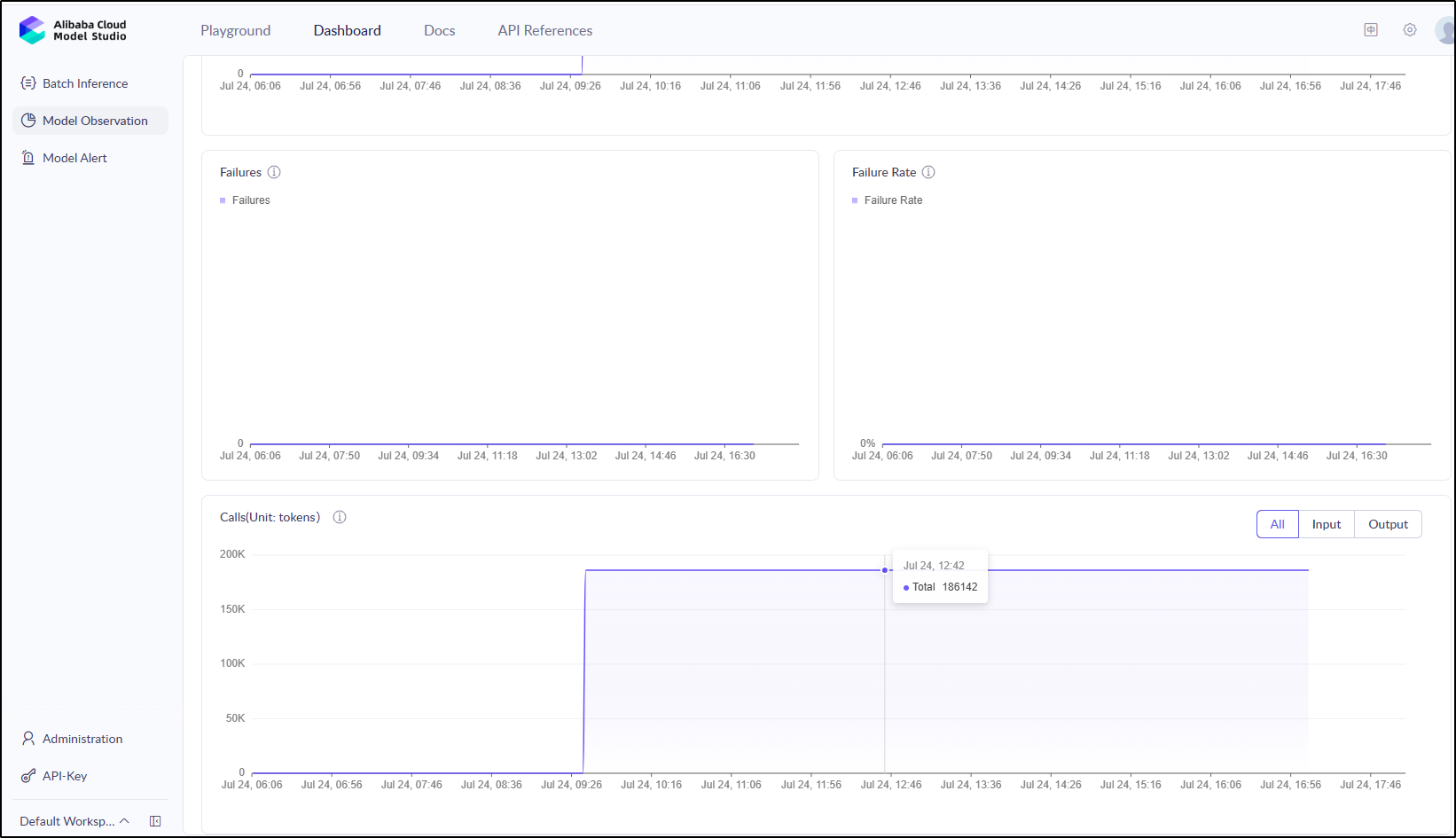
The outputs
The diagrams look pretty good. There are a lot of them
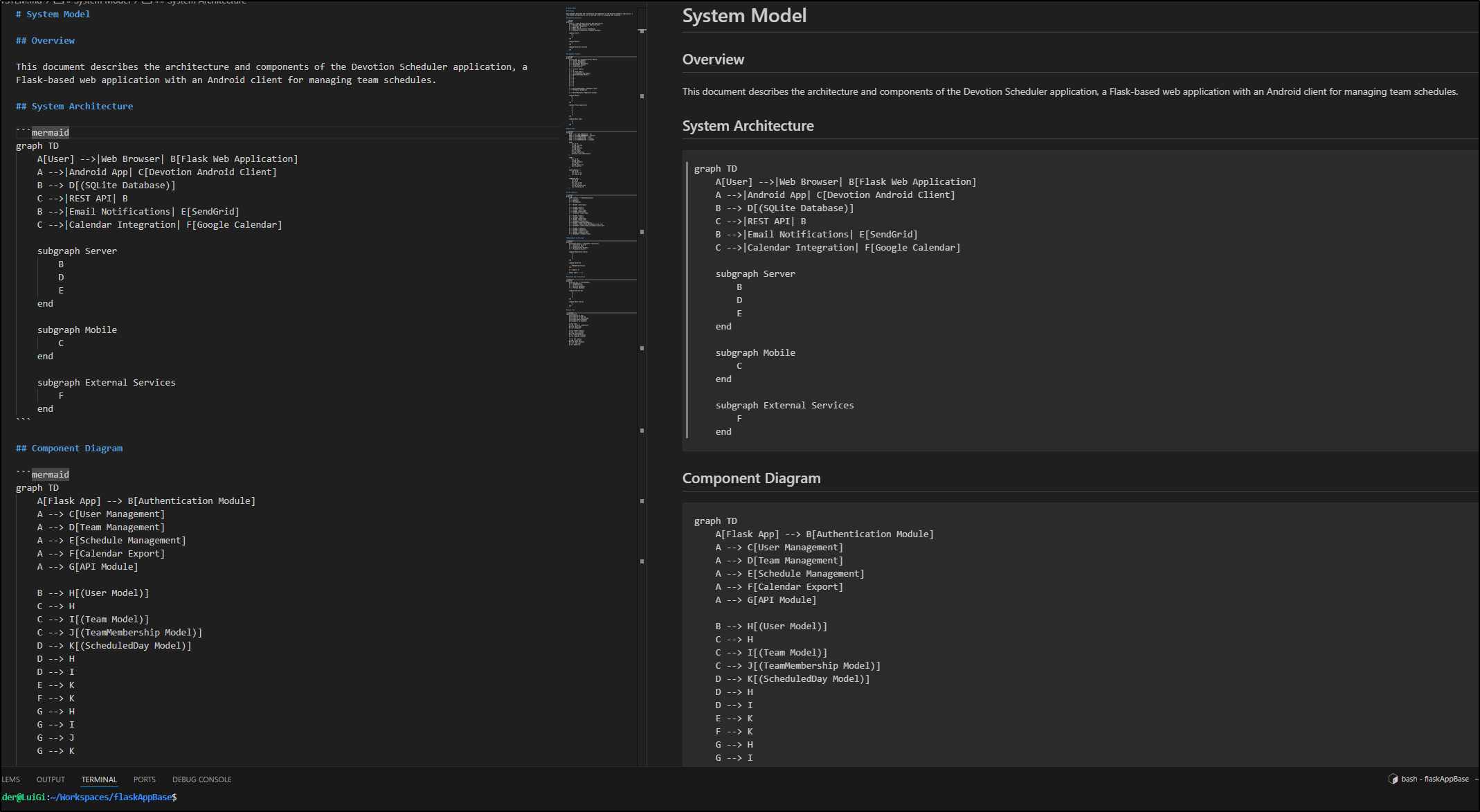
I’m going to push up to a branch on Forgejo so I can view them
builder@LuiGi:~/Workspaces/flaskAppBase$ git checkout -b example-qwen
Switched to a new branch 'example-qwen'
builder@LuiGi:~/Workspaces/flaskAppBase$ git add SYSTEM.md
builder@LuiGi:~/Workspaces/flaskAppBase$ git commit -m "Qwen3 diagrams"
[example-qwen f9f2a6c] Qwen3 diagrams
1 file changed, 244 insertions(+)
create mode 100644 SYSTEM.md
builder@LuiGi:~/Workspaces/flaskAppBase$ git push
fatal: The current branch example-qwen has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin example-qwen
To have this happen automatically for branches without a tracking
upstream, see 'push.autoSetupRemote' in 'git help config'.
builder@LuiGi:~/Workspaces/flaskAppBase$ git push --set-upstream origin example-qwen
Enumerating objects: 22, done.
Counting objects: 100% (21/21), done.
Delta compression using up to 16 threads
Compressing objects: 100% (14/14), done.
Writing objects: 100% (14/14), 5.35 KiB | 684.00 KiB/s, done.
Total 14 (delta 7), reused 0 (delta 0), pack-reused 0 (from 0)
remote:
remote: Create a new pull request for 'example-qwen':
remote: https://forgejo.freshbrewed.science/builderadmin/flaskAppBase/compare/main...example-qwen
remote:
remote: . Processing 1 references
remote: Processed 1 references in total
To https://forgejo.freshbrewed.science/builderadmin/flaskAppBase.git
* [new branch] example-qwen -> example-qwen
branch 'example-qwen' set up to track 'origin/example-qwen'.
I’ll create a PR
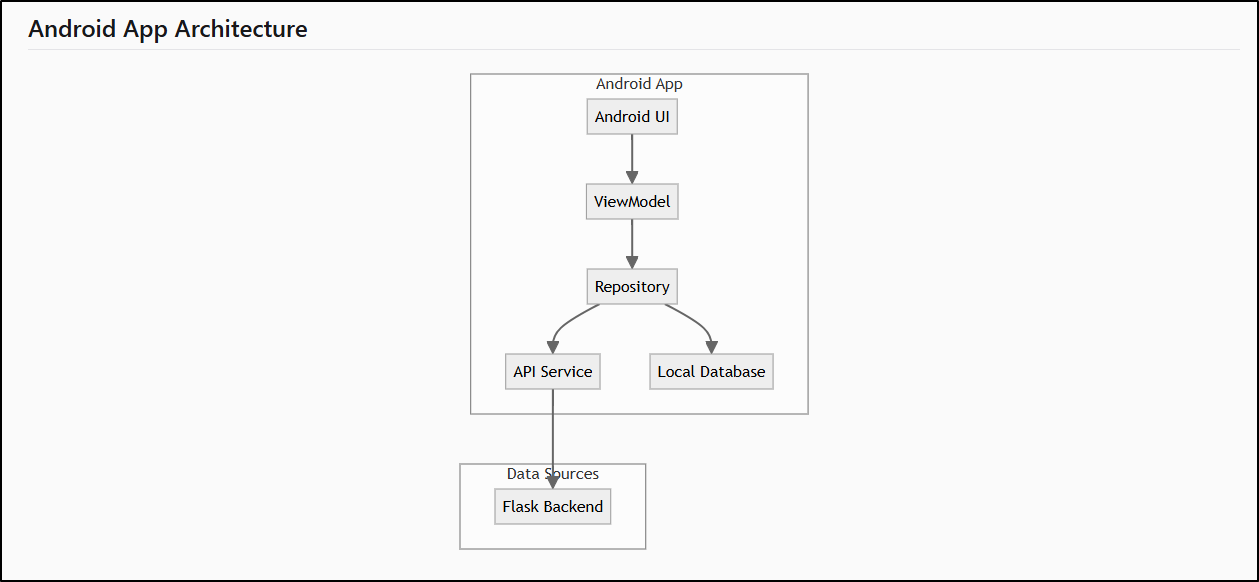
Now viewing the files shows it picked up an unreleased Android App I was working on and added that to my models
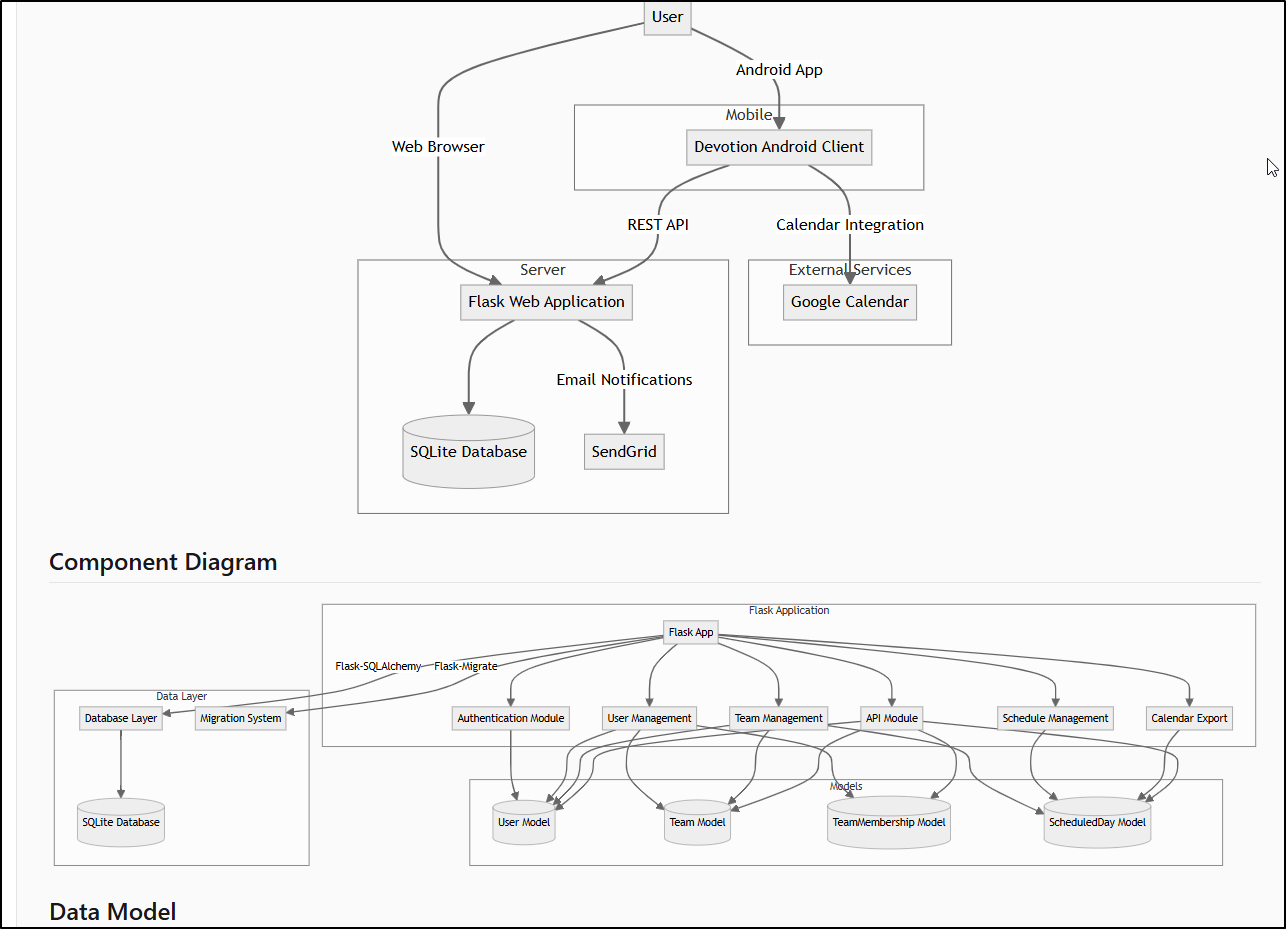
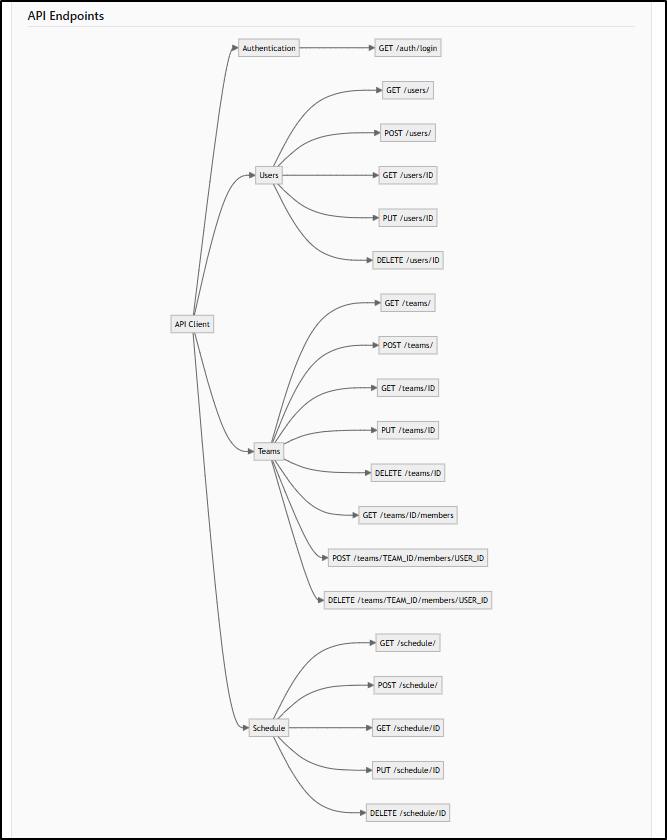
While it did an amazing job of modeling my data model, it did make a minor mistake documenting API endpoints
But seriously, this really knocked it out of the park. I have deployment diagrams
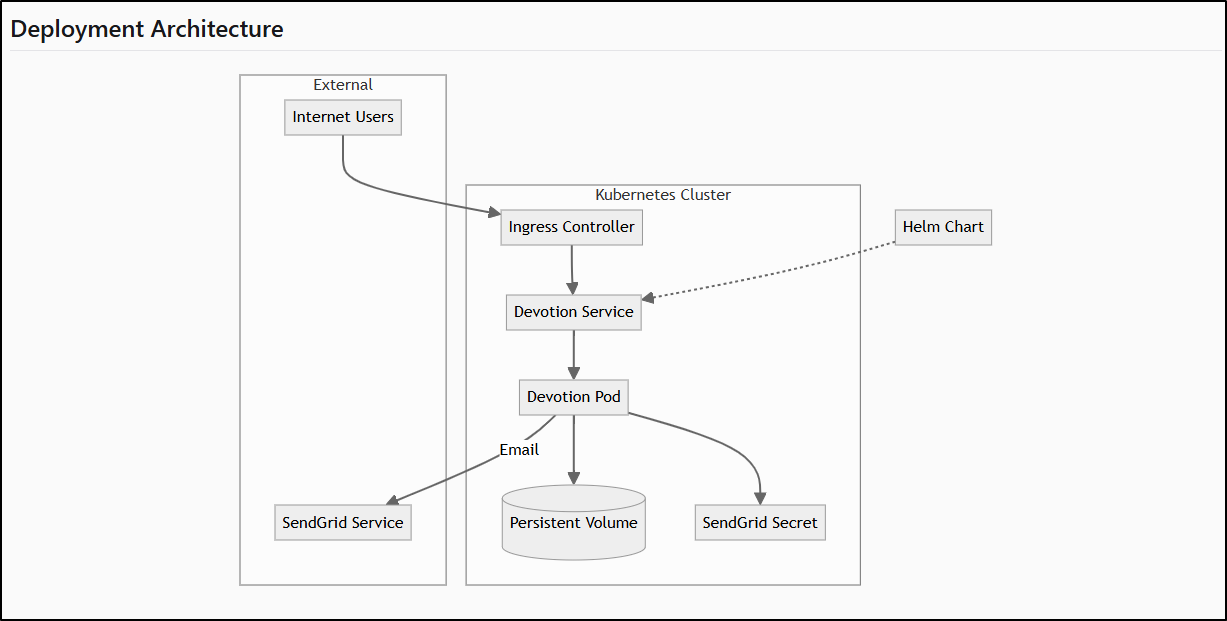
The Android App Architecture
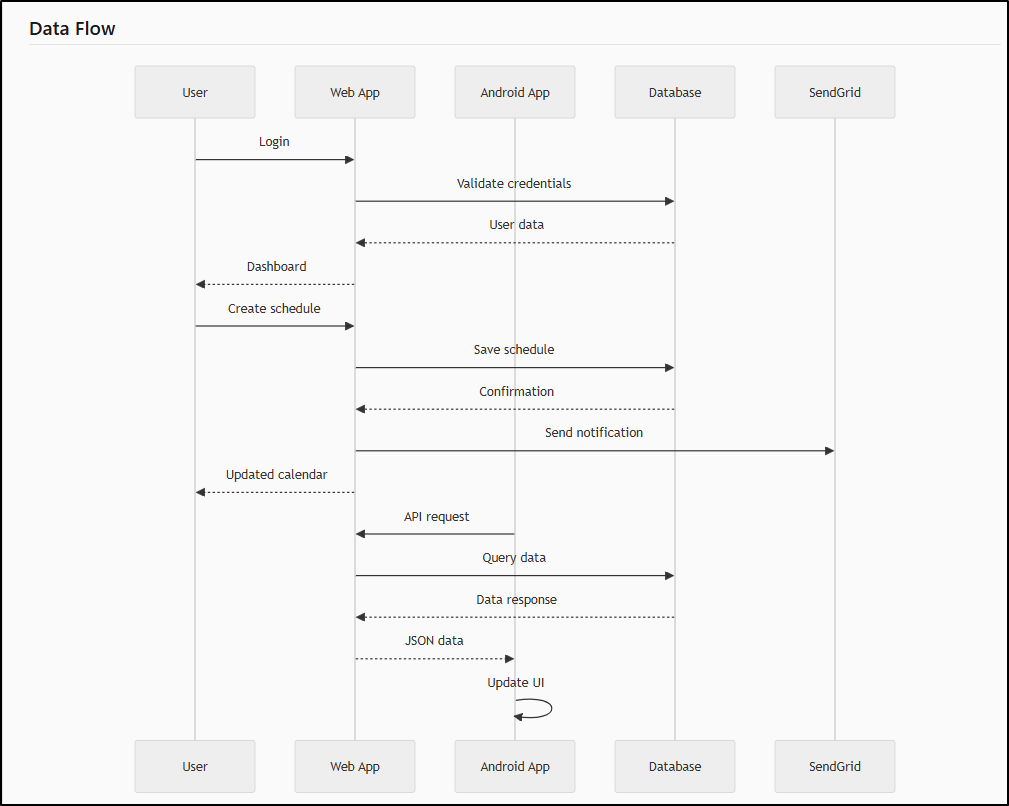
and lastly Data flow
Here I fixed the API Endpoint diagram
Costs
It would appear that Qwen3-Coder-Plus might run us $0.40/million input tokens.
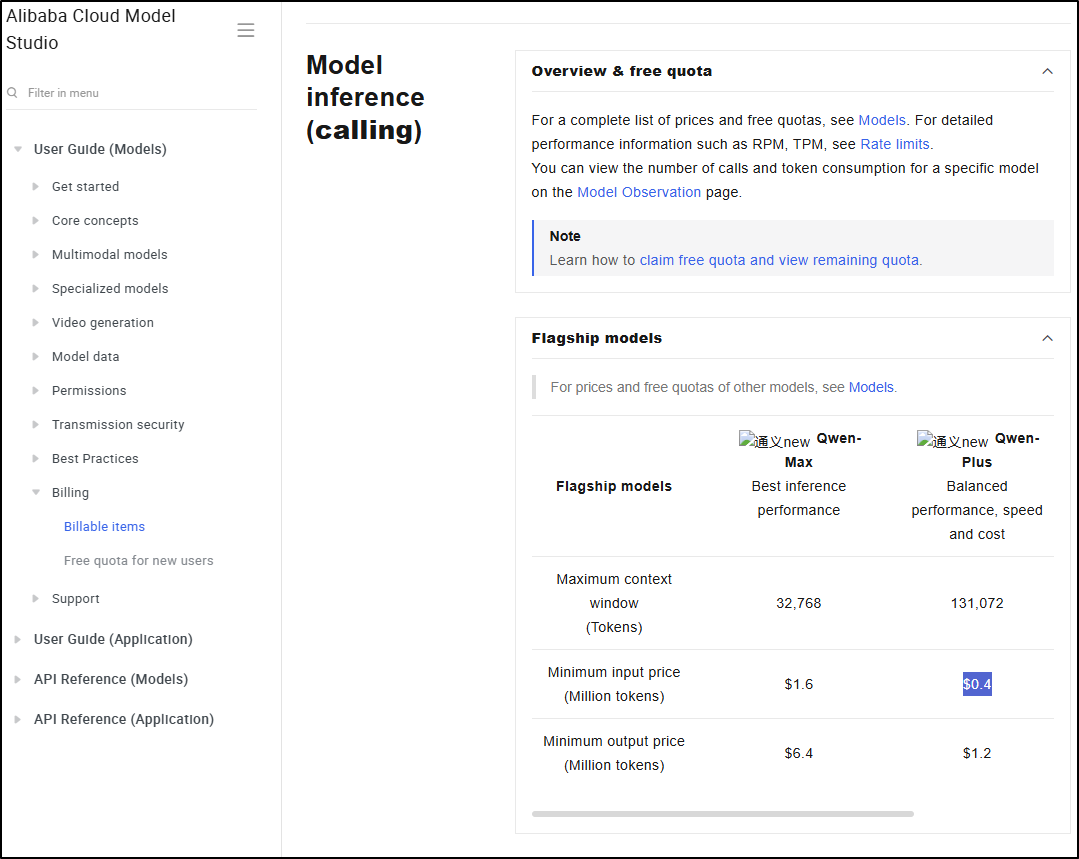
Thus, by my math, my SYSTEM.md call might have cost me about 7 cents if I did not have free tokens - that is a lot less than I would pay for Claude Code.
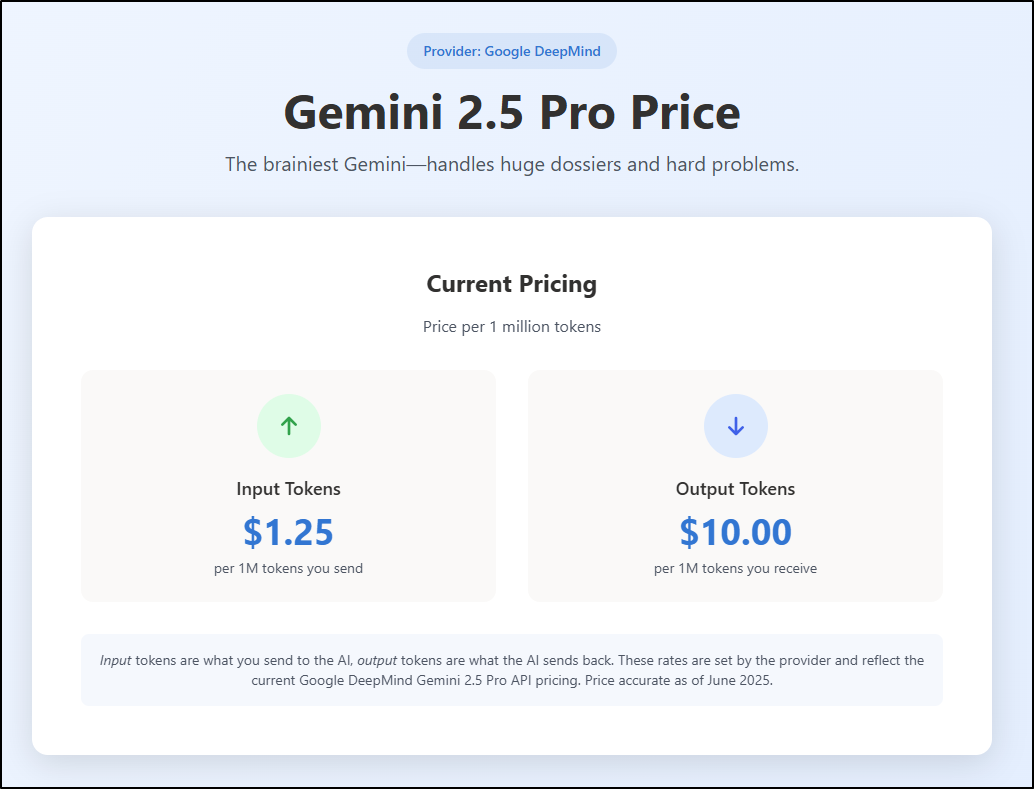
The costs of Gemini Pro are presently $1.25/million input tokens, but we also get charges for output as well. While that is more, consider also that Gemini Pro covers more as well.
Local and Self-Hosted
Because this can engage in OpenAI’s SDK endpoint, we can actually use Gwen to use our own hardware and models
Spoiler: no we cannot - but I’ll certainly try below
And if my remote agent is falling down as it is today
For instance, my WSL has Ollama serving a few models presently
builder@LuiGi:~$ ollama list
NAME ID SIZE MODIFIED
nomic-embed-text:latest 0a109f422b47 274 MB 5 weeks ago
qwen2.5-coder:1.5b-base 02e0f2817a89 986 MB 3 months ago
llama3.1:8b 46e0c10c039e 4.9 GB 5 months ago
qwen2.5-coder:7b 2b0496514337 4.7 GB 5 months ago
starcoder2:3b 9f4ae0aff61e 1.7 GB 5 months ago
which is easy to use the the URL http://127.0.0.1:11434/v1
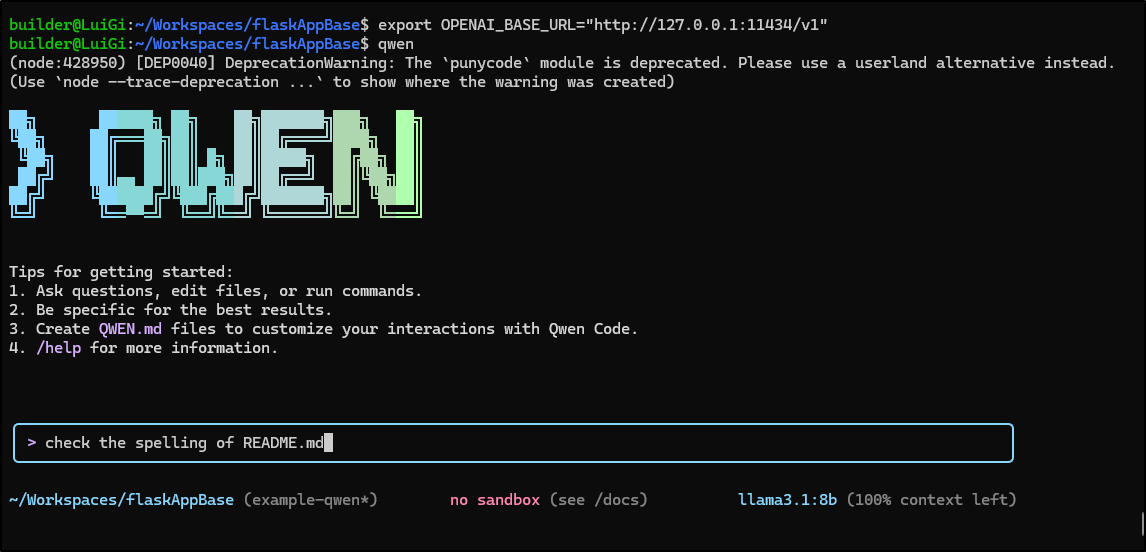
This highlighted an issue with all my docker containers and apps running - not enough memory
$ ollama pull qwen3:4b
pulling manifest
pulling 163553aea1b1: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 2.6 GB
pulling ae370d884f10: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 1.7 KB
pulling d18a5cc71b84: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB
pulling cff3f395ef37: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 120 B
pulling 5efd52d6d9f2: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
Let’s try it
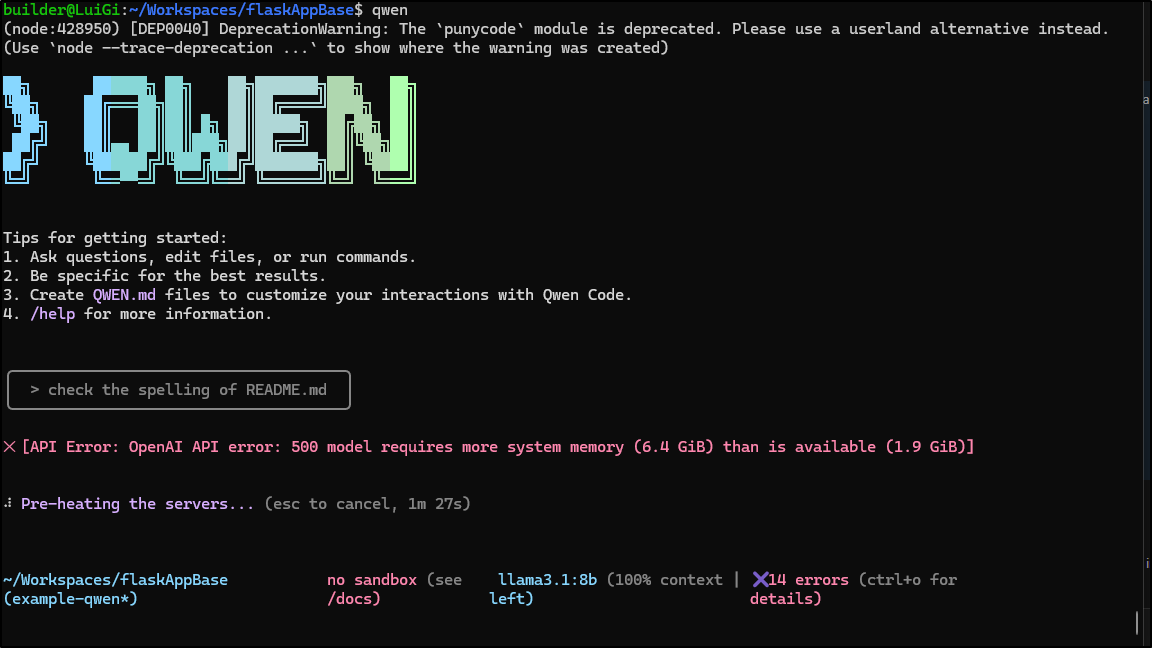
builder@LuiGi:~/Workspaces/jekyll-blog$ export OPENAI_MODEL="qwen3:4b"
builder@LuiGi:~/Workspaces/jekyll-blog$ export OPENAI_BASE_URL="http://localhost:11434/v1"
builder@LuiGi:~/Workspaces/jekyll-blog$ export OPENAI_API_KEY="notused"
builder@LuiGi:~/Workspaces/jekyll-blog$
When I’m running this, I do see it peg the CPU
$ ollama ps
NAME ID SIZE PROCESSOR UNTIL
qwen3:4b 2bfd38a7daaf 4.7 GB 100% CPU 4 minutes from now
I really couldn’t get this to work, however.
Even in an empty directory with a simple prompt, it went out to lunch
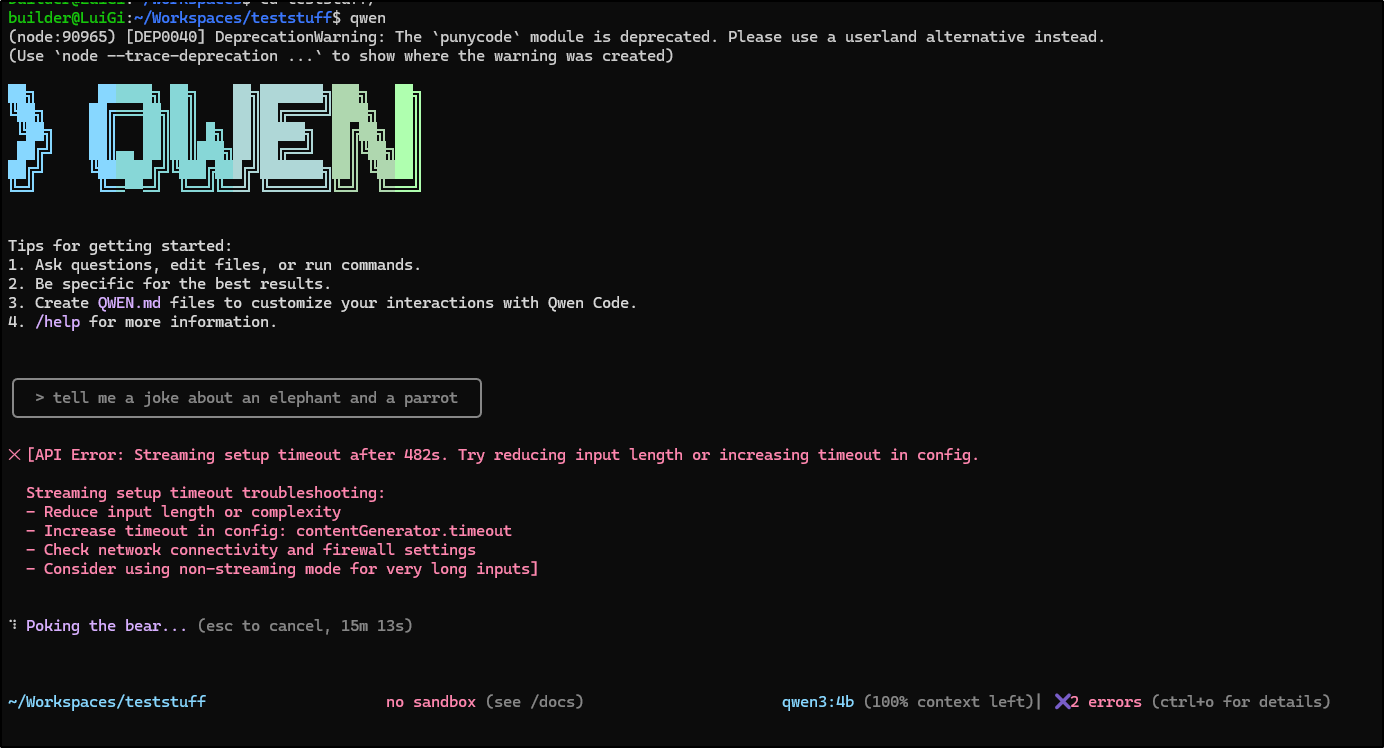
Ollama
Ollama cannot access local files otherwise that could work
I’m going to try adding Ollama to my larger Windows gaming PC that has a bigger RTX graphics card
First, I check that Ollama isn’t running
PS C:\Users\isaac> ollama list
ollama : The term 'ollama' is not recognized as the name of a cmdlet, function, script file, or operable program.
Check the spelling of the name, or if a path was included, verify that the path is correct and try again.
At line:1 char:1
+ ollama list
+ ~~~~~~
+ CategoryInfo : ObjectNotFound: (ollama:String) [], CommandNotFoundException
+ FullyQualifiedErrorId : CommandNotFoundException
I then download Ollama and try running a model
PS C:\Users\isaac> ollama run gemma3
pulling manifest
pulling aeda25e63ebd: 100% ▕██████████████████████████████████████████████████████████▏ 3.3 GB
pulling e0a42594d802: 100% ▕██████████████████████████████████████████████████████████▏ 358 B
pulling dd084c7d92a3: 100% ▕██████████████████████████████████████████████████████████▏ 8.4 KB
pulling 3116c5225075: 100% ▕██████████████████████████████████████████████████████████▏ 77 B
pulling b6ae5839783f: 100% ▕██████████████████████████████████████████████████████████▏ 489 B
verifying sha256 digest
writing manifest
success
>>> tell me a joke about an elephant and a parrot
Okay, here’s a joke for you:
Why did the elephant break up with the parrot?
... Because he said she was always squawking!
---
Would you like to hear another joke? 😊
>>>
Use Ctrl + d or /bye to exit.
>>>
Use Ctrl + d or /bye to exit.
>>>
PS C:\Users\isaac> ollama ps
NAME ID SIZE PROCESSOR UNTIL
gemma3:latest a2af6cc3eb7f 6.3 GB 41%/59% CPU/GPU 4 minutes from now
I believe WSL can reach the Ollama served in Windows natively, but I have yet to try it.
Let’s add QWen3 Coder locally
builder@DESKTOP-QADGF36:~/Workspaces/gancio$ npm i -g @qwen-code/qwen-code
added 1 package in 1s
npm notice
npm notice New major version of npm available! 10.8.2 -> 11.5.1
npm notice Changelog: https://github.com/npm/cli/releases/tag/v11.5.1
npm notice To update run: npm install -g npm@11.5.1
npm notice
I gave it a test but it didn’t seem to connect
Same with using the local Windows IP instead of localhost
Gemini CLI with Qwen
Another interesting tactic we can take is to use the Gemini CLI, but have the Vertex AI backend use the Qwen model
$ gemini --model qwen3
Well, it should have worked but didn’t (I tried qwen3 and Qwen3)
I also tried with Azure AI Foundry but that too gave an error:
✕ [API Error: OpenAI API error: 404 Resource not found]
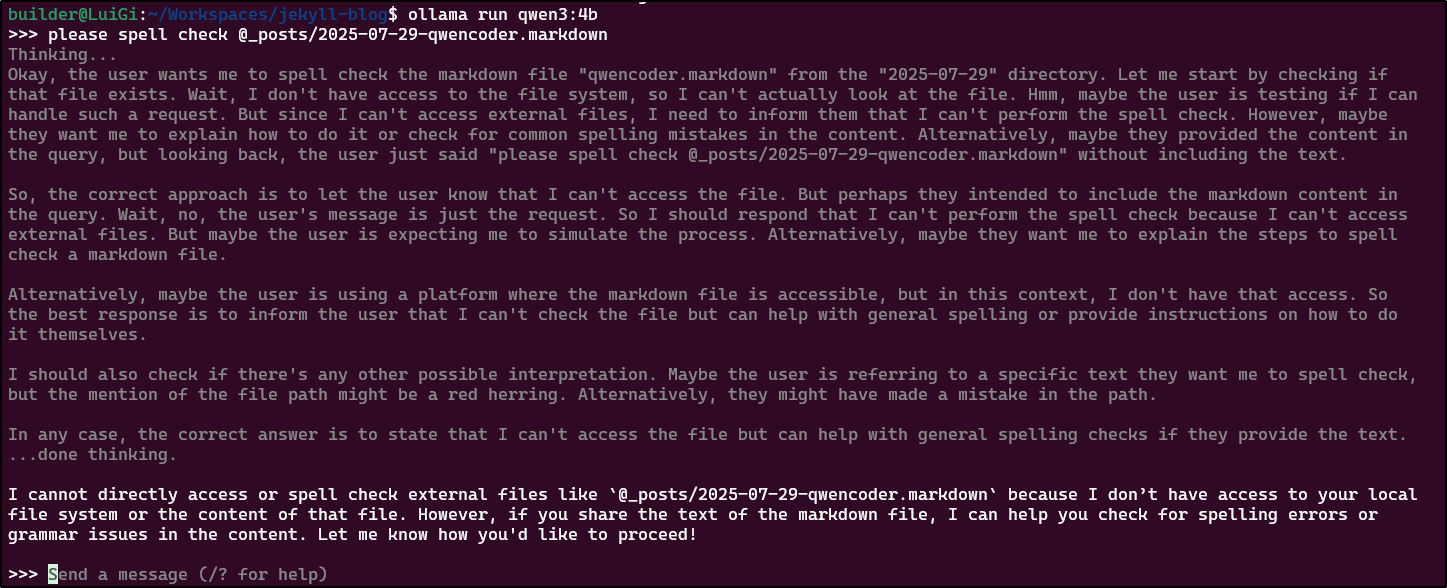
I was worried about my local env. I could verify I could spell check with Gemini 2.5 Pro
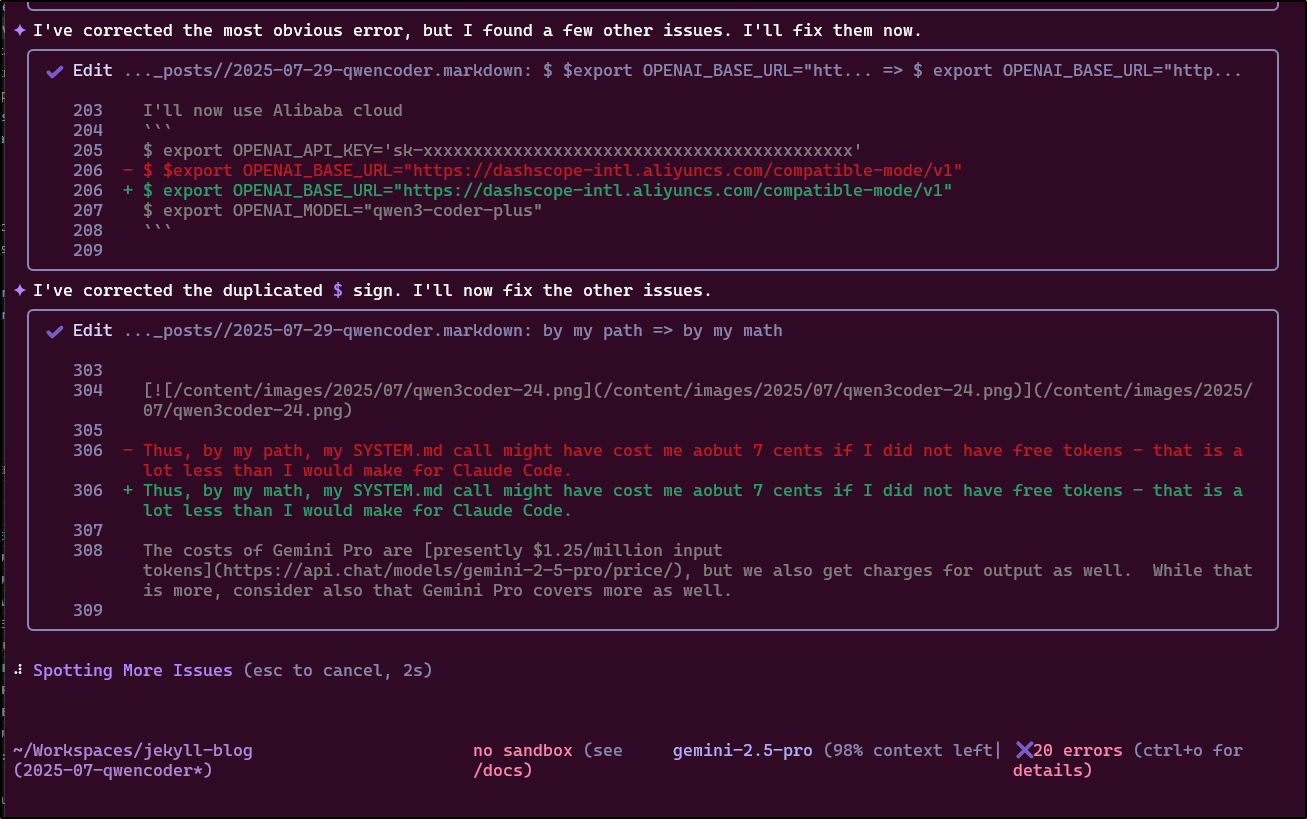
My only issue with doing it this way is that when it is wrong (like suggesting Claude Sonnet instead of Claude Code which is what I meant) and I say “No”, it stops with any other suggestions
That said, I could just use aspell in interactive mode and avoid AIs altogether
$ aspell -c _posts/2025-07-29-qwencoder.markdown
Continue.dev
I had one more idea to try Qwen3 out, albeit the standard OS model not the “Coder-Pro”
I added a section to my continue.dev config.json
{
"model": "qwen3:latest",
"apiBase": "http://localhost:11434",
"provider": "ollama",
"title": "Ollama Qwen3 (PC)"
},
Which worked great (I mean, the joke is terrible, but that is to be expected)
I often think of the AI telling jokes as an elementary age kid repeating a joke but getting it just a bit off…
A real test
Let’s update the python-kasa app which I mistakenly removed GET operations when I updated to FastAPI a few weeks back.
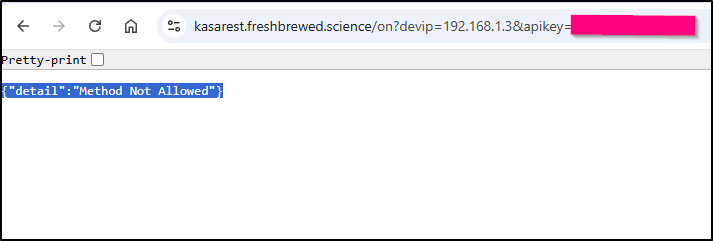
I’ll ask Qwen to help
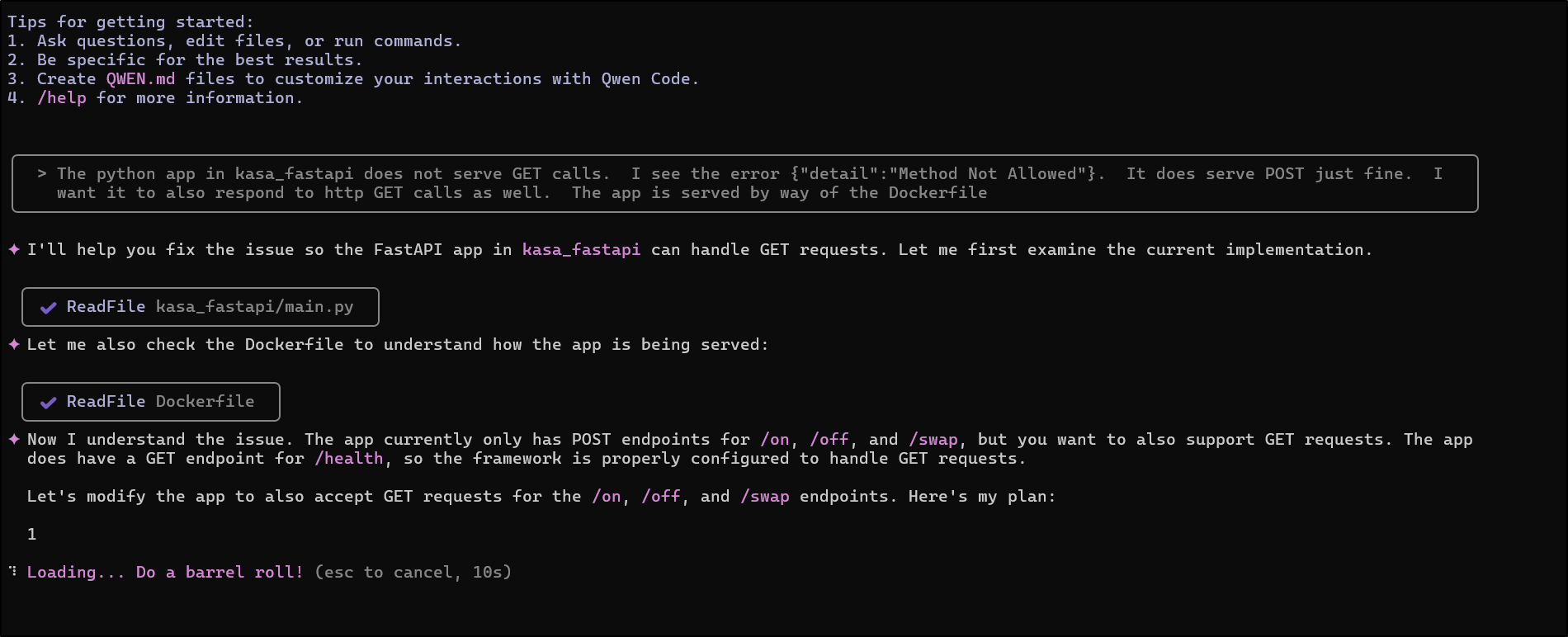
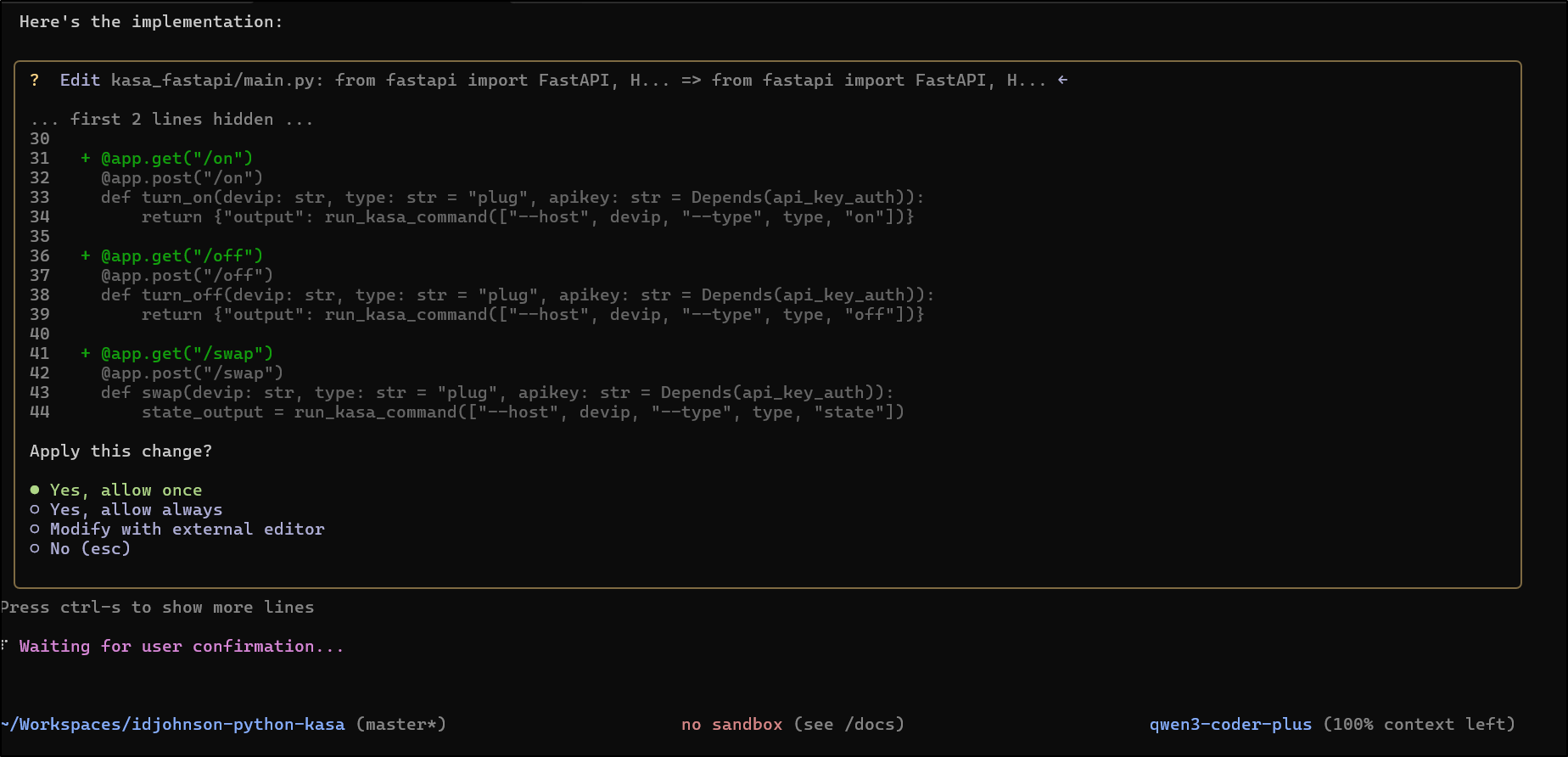
It proposed a fix
It tried to test changes but got a bit hung up on those steps

I let it go for a bit before I stopped it from getting too deep in testing
The change seems quite clear
$ git diff kasa_fastapi/main.py
diff --git a/kasa_fastapi/main.py b/kasa_fastapi/main.py
index 93519e9..0a52c5b 100644
--- a/kasa_fastapi/main.py
+++ b/kasa_fastapi/main.py
@@ -28,14 +28,17 @@ def run_kasa_command(command: list[str]):
def health_check():
return {"status": "ok"}
+@app.get("/on")
@app.post("/on")
def turn_on(devip: str, type: str = "plug", apikey: str = Depends(api_key_auth)):
return {"output": run_kasa_command(["--host", devip, "--type", type, "on"])}
+@app.get("/off")
@app.post("/off")
def turn_off(devip: str, type: str = "plug", apikey: str = Depends(api_key_auth)):
return {"output": run_kasa_command(["--host", devip, "--type", type, "off"])}
+@app.get("/swap")
@app.post("/swap")
def swap(devip: str, type: str = "plug", apikey: str = Depends(api_key_auth)):
state_output = run_kasa_command(["--host", devip, "--type", type, "state"])
I pushed to master and waited for the build to complete
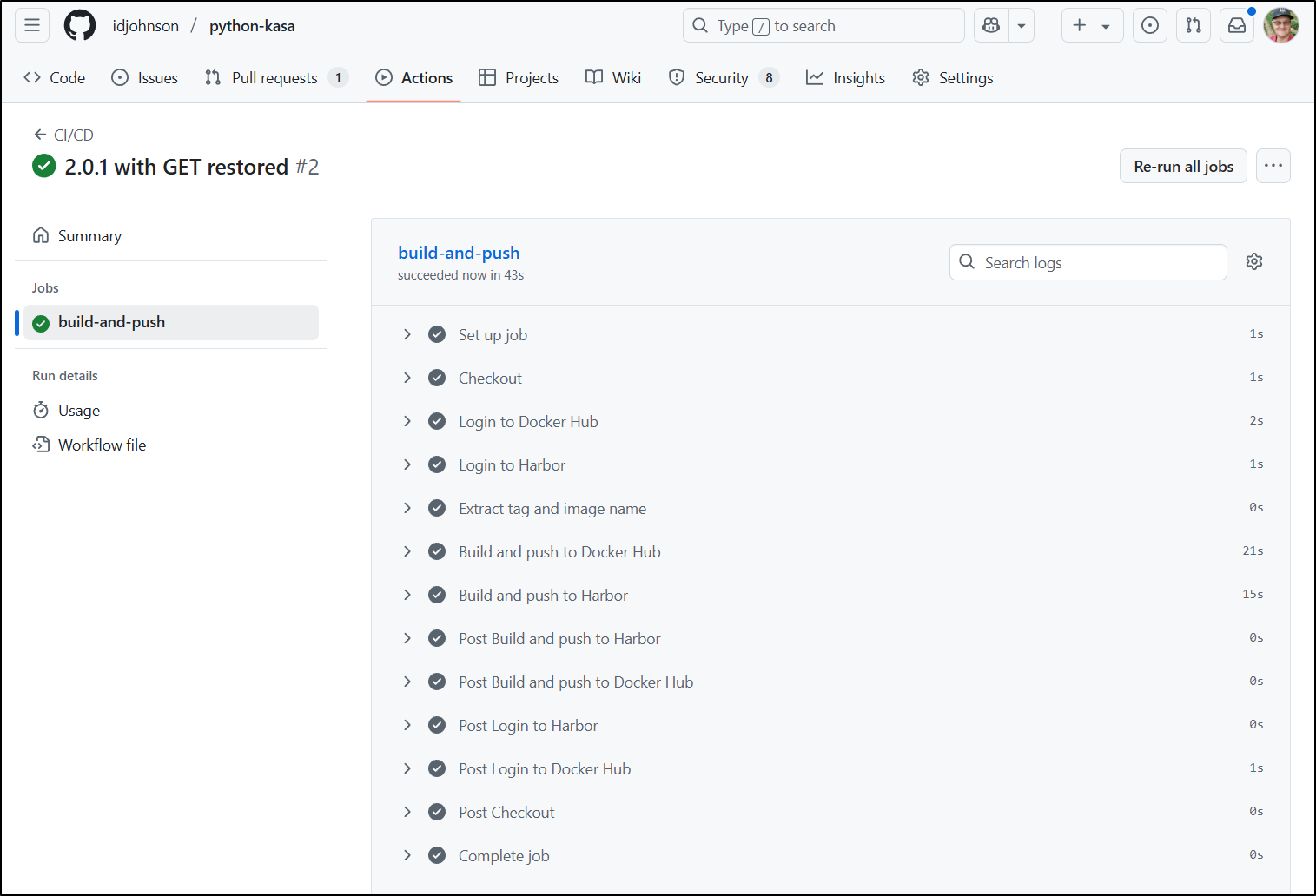
And now it works!
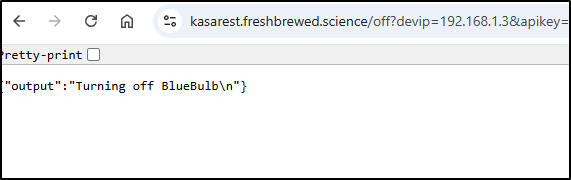
I also got tired of remembering where my charts where so I merged in the updated charts from the feature branch to master so all could use them
Costs
So late in the evening on Sunday I get a call from an Alabama number. Out of sheer curiosity I took it and it ended up being a very nice lady with a strong Chinese accent. There was a long pause between talking so I assume she was doing some translating.
But she identified herself as being from AliCloud and wanted to know how I planned to use their AI Model Studio and if I had any questions.
She sent me the current price sheet which makes me second guess their numbers:
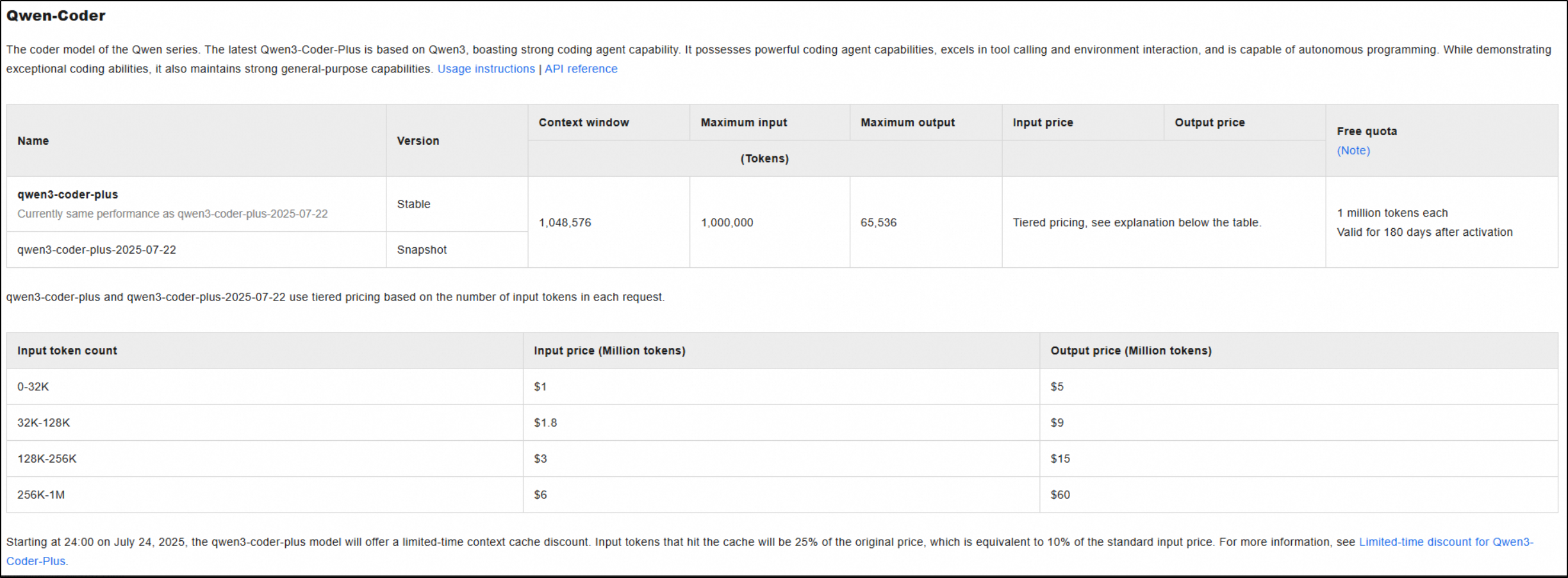
According to Lucy from Alibaba Cloud, “The per million price depends on how many tokens you have consumed, the more you consume, the unit price would be higher. Please check the screen shot for details”
So if you use up to 32k tokens then it’s $1/million price. Basically up to 32k tokens (input) that is $0.032 However 128K would be $0.2304 (not 0.032*4, 0.128). So it gets more expensive the more tokens - it’s not a flat scale.
However, I did check the following Monday and I was still not charged which was good
Telemetry
While I do not know if it uses the .gemeni config file, I do see we can pass the Telemetry flags to Qwen3 Coder just as easily
Since I have an Alloy OTel collector running already, let’s try sending OTLP metrics to it.
builder@DESKTOP-QADGF36:~/Workspaces/idjohnson-python-kasa$ export OPENAI_API_KEY='sk-xxxxxxxxxxxxxxxxxxxxxx'
builder@DESKTOP-QADGF36:~/Workspaces/idjohnson-python-kasa$ export OPENAI_BASE_URL="https://dashscope-intl.aliyuncs.com/compatible-mode/v1"
builder@DESKTOP-QADGF36:~/Workspaces/idjohnson-python-kasa$ export OPENAI_MODEL="qwen3-coder-plus"
builder@DESKTOP-QADGF36:~/Workspaces/idjohnson-python-kasa$ qwen --telemetry --telemetry-target=local --telemetry-otlp-endpoint=http://192.168.1.33:30921 --telemetry-log-prompts
I’ll ask it to create a SYSTEM.md with diagrams
And it seemed to create them
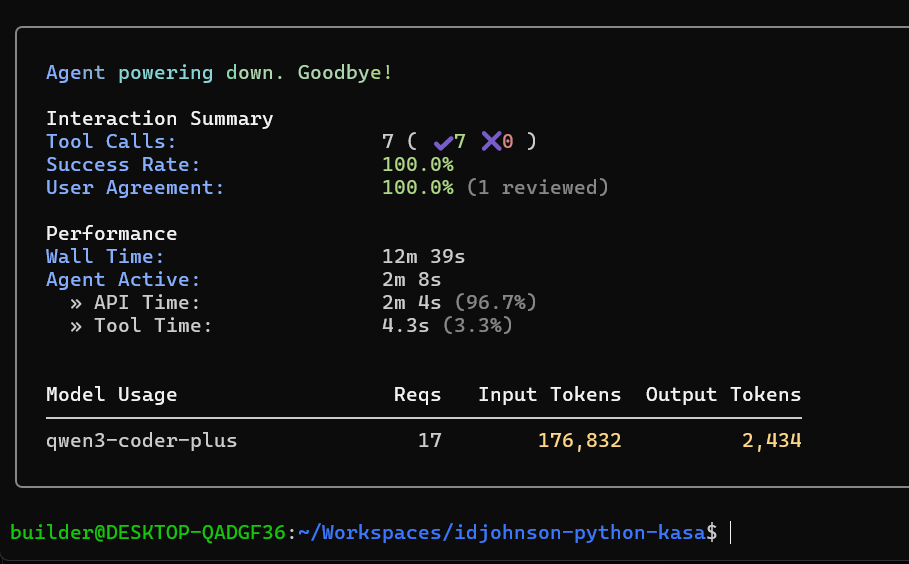
I can see we used some tokens
Since as of the last write-up we sent our Alloy OTLP to Datadog, I can go to Datadog to now see the details
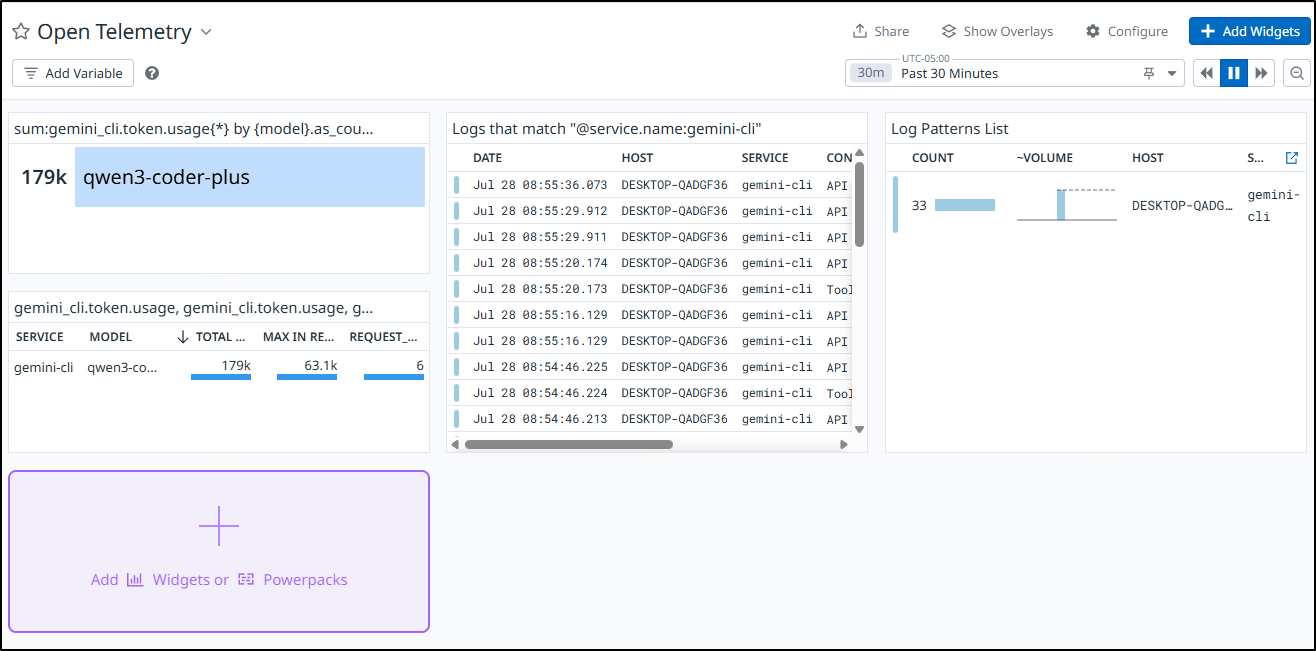
What is nice about collecting all our telemetry in a single pane of glass is that we can view our usage by model which would be good for cost considerations
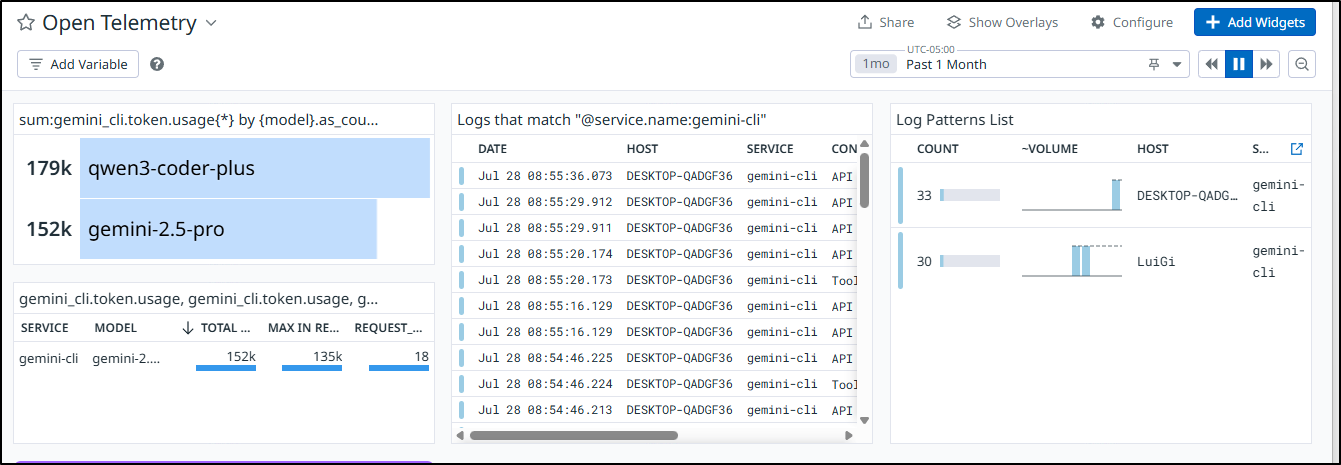
outputs
I don’t want to gloss over the output QWen3 gave us because it is really are quite amazing.
I tested each diagram output in Mermaid.live and found no errors so I pushed it verbatim up to Github
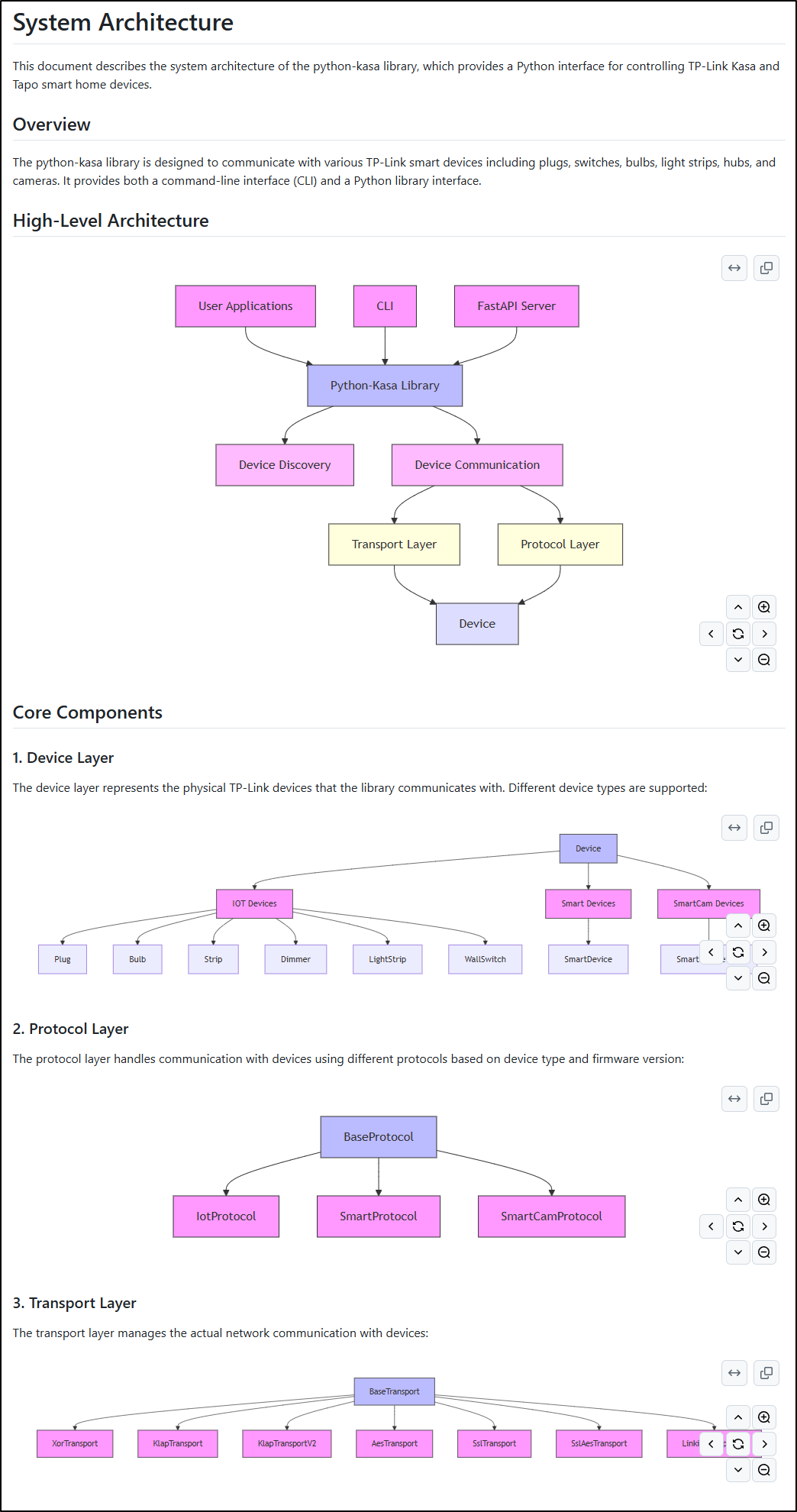
Head over to SYSTEM.md on the rpoject and we can see High-level and Core Components:
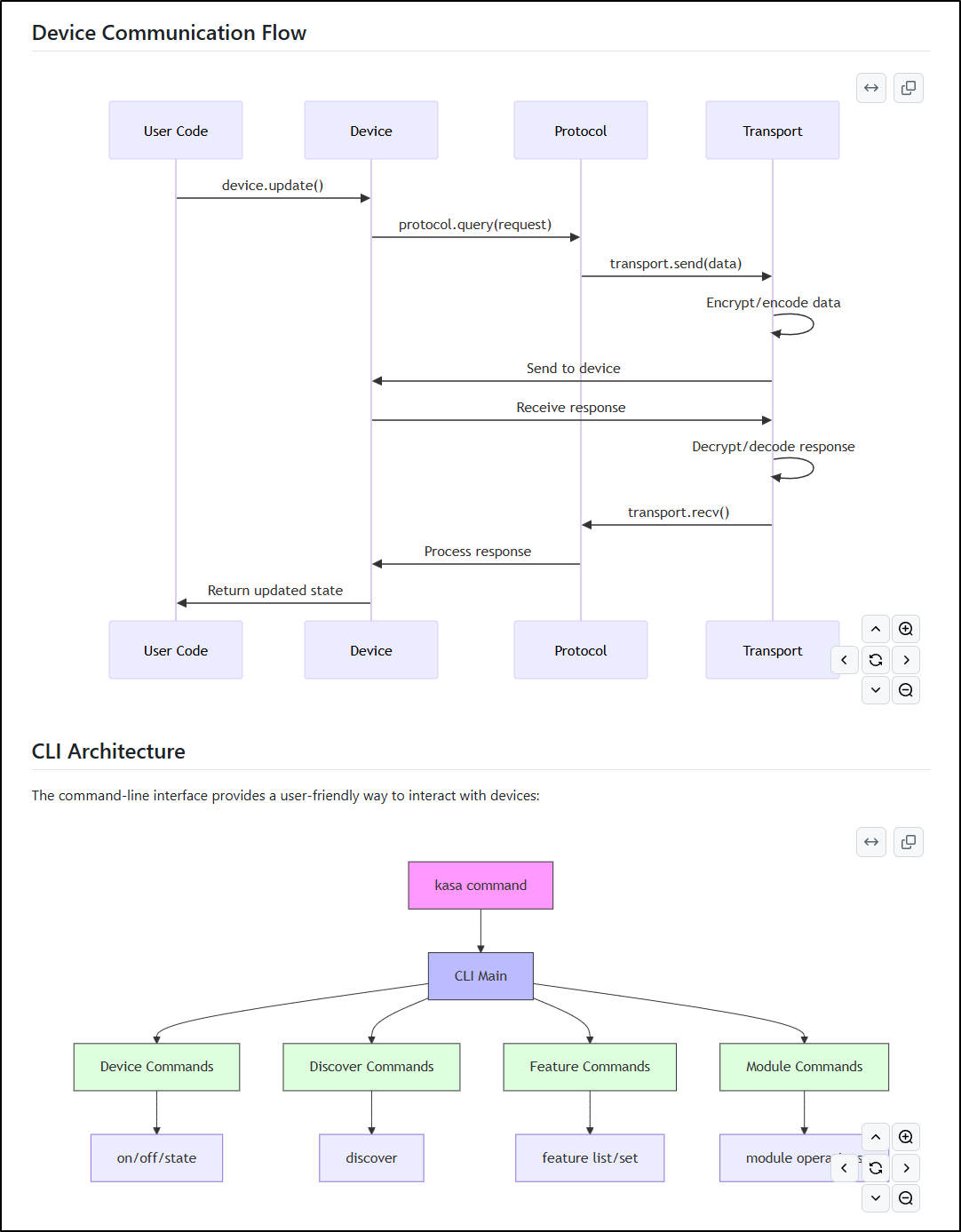
Device Flow and CLI Architecture:
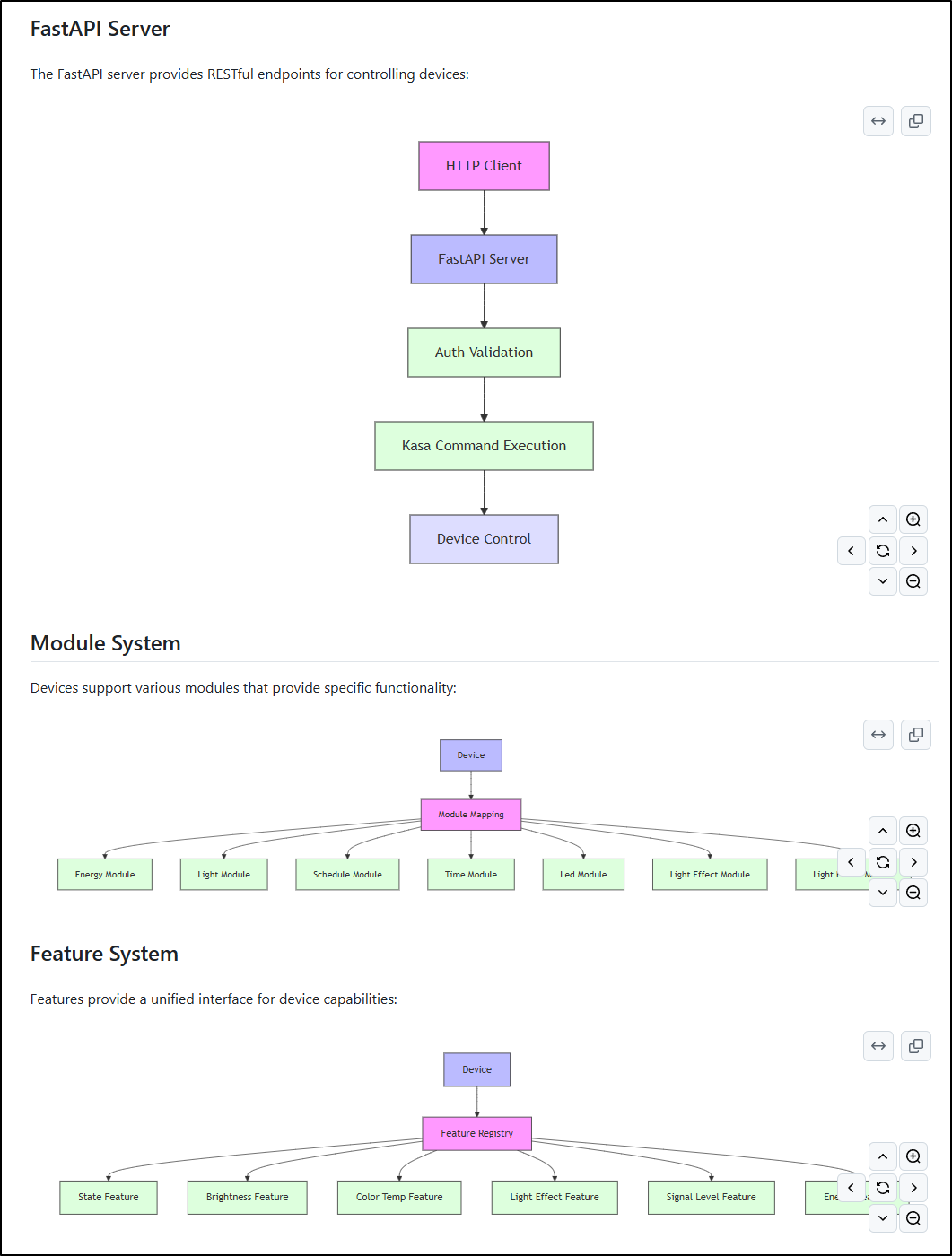
FastAPI, Module and System diagrams:
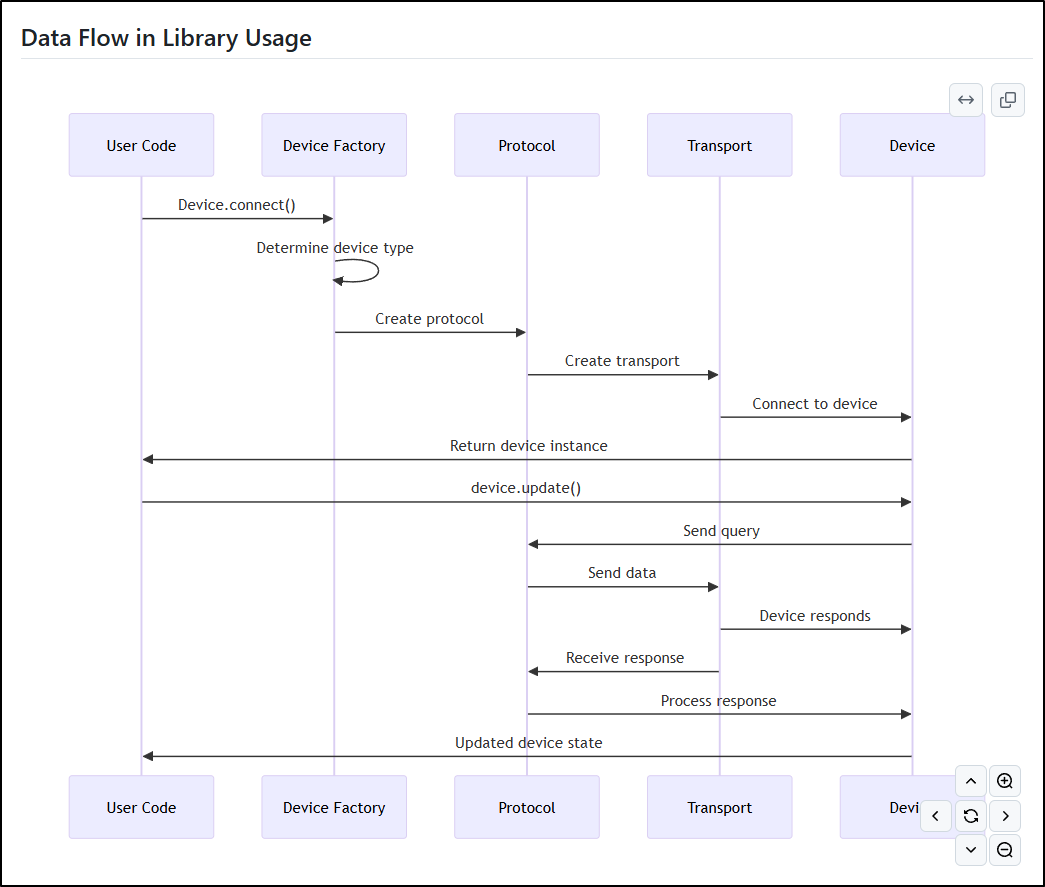
And lastly the Data Flow in Library Usage:
Pricing
So based on our pricing chart, IF i had to pay for that (and wasn’t in my “free tier” of an initial 1M tokens), the 179k input tokens would have been $0.537 and the 2434 output tokens would be $0.01217 so basically this would be a 54c query.
and based on the Gemini pricing
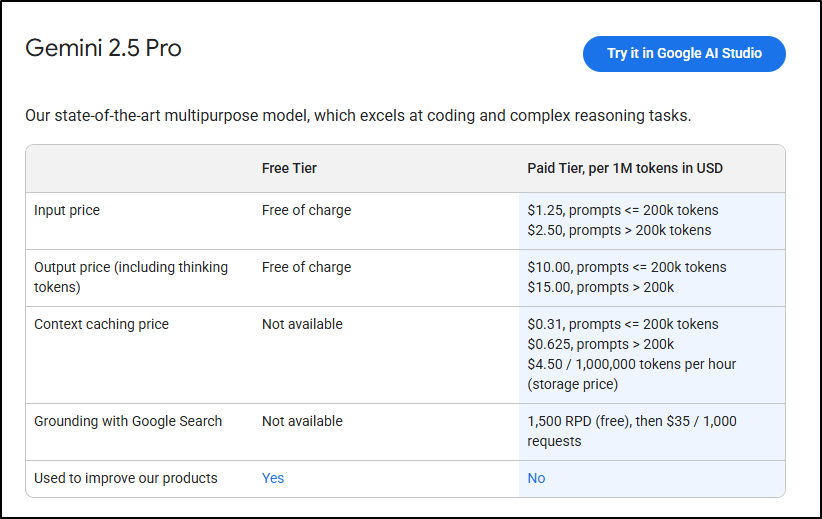
It would be $0.22375 for 179k input tokens and $0.02434 for the 2434 output tokens rendering a price of about 25c.
So basically what we learn here is AFTER we use up the million, QWen3 will be TWICE the price of Gemini 2.5 Pro.
According to current Claude pricing, Sonnet 4 would be $0.03651 for the output tokens and $0.537 for the input for a total of $0.57
So our totals for this System diagram we did about would be (USD):
- Claude (Sonnet 4): $0.57351
- QWen3 (Coder Pro): $0.54917
- Gemini Pro (2.5): $0.24809
The part that might really get people would be the output tokens.
At 1M - if you really made a lot of stuff, that would $60 in Gwen3 (Alicloud), $15 for Claude and Gemini Pro.
Summary
Qwen3 Coder might be seen as just another “me too” on the CLI coding assistant space if it weren’t for the model and pricing. The Qwen3 Coder Pro model is really quite amazing. I have barely scratched the surface but it would seem a very cost effective offering when lined up against Anthropic’s Claude Code.
One of the things that caught me was the OPENAI variables - I really thought I could shoe-horn in other models, but time and time again, that just would not work.
My new approach is simply:
- When looking for something turnkey and agentic, use Gemini CLI, Claude Code and now Qwen3 Coder
- When looking to stay in my editor, use Gemini Code Assist and Copilot
- When looking to use my local models, use the continue.dev plugin for VS Code
The other thing I’m guilty of is “new hammer” syndrome. I’m just looking to whack every problem with an AI. Half-way through trying to get the AI tools to spell check, I figured out there is a perfectly good local Linux app, aspell and to my shame, I realized it has been around since 2004.
Perhaps, if anything, that should be my takeaway: check if there is a tool that already exists before tossing tokens to the AIs to solve problems.
